Recurrent Network - 2nd Part
LSTM was proposed in 1997 by Sepp Hochreiter and Jürgen Schmidhuber. It is an artificial recurrent neural network (RNN) architecture, developed to deal with the exploding and vanishing gradient problems that can be encountered when training traditional RNNs.
In this lessson, we would introduce several parts below:
- Some application of LSTM, eg., Seq2Seq
1.1 Naive implementation of Seqseq translation model
1.2 Naive implementation of Seqseq translation model with attention mechanism - More about LSTM
2.1 Exploring the inner structrue of LSTM (Implement LSTM from scratch using pytorch)
2.2 Comparing LSTM with RNN on change of the grad, when input is a very long sequence
2.3 Observing the forget gate, input gate and output gate of LSTM
This tutorials mainly refer from seq2seq_translation_tutorial and Building an LSTM from Scratch in PyTorch .
Load Necessary modules
%load_ext autoreload
%autoreload 2
%matplotlib inline
import random
import math
import time
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
from typing import *
from torch.nn import Parameter
from torch.nn import init
from torch import Tensor
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
Since process of data isn’t the center part that we should focus in this tutorials,
we put data related code in utils function.
Actually, if we want to solve a problem seriously, there is no way for us to skip data processing, which may be boring but very important.
from utils import *
# Determine to use GPU or CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def setup_seed(seed):
"""In order to reproduce the same results
Args:
seed: random seed given by you
"""
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
1.1 Naive implementation of Seqseq translation model
Seq2seq translation model consists of two parts, including the Encoder and Decoder.
Encoder encodes source sentences into fixed vectors for decoder.
Decoder decode fixed vectors into target sentences.

1.1.1 The Encoder
The encoder of a seq2seq network is a LSTM that outputs some value for every word from the input sentence.
For every input word the encoder outputs a vector and a hidden state, and uses the hidden state for the
next input word.
class EncoderLSTM(nn.Module):
"""Encoder use LSTM as backbone"""
def __init__(self, input_size: int, hidden_size: int):
"""
Args:
input_size : The number of expected features in the input
hidden_size: The number of features in the hidden state
"""
super(EncoderLSTM, self).__init__()
self.hidden_size = hidden_size
# Retrieve word embeddings with dimentionality hidden_size
# using indices with dimentionality input_size, embeddding is learnable
# After embedding, input vector with input_size would be converted to hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
# LSTM
self.lstm = nn.LSTM(hidden_size, hidden_size)
def forward(self, inputs: Tensor, state: Tuple[Tensor]):
"""Forward
Args:
inputs: [1, hidden_size]
state : ([1, 1, hidden_size], [1, 1, hidden_size])
Returns:
output:
state: (hidden, cell)
"""
(hidden, cell) = state
# Retrieve word embeddings
embedded = self.embedding(inputs).view(1, 1, -1)
# Directly output embedding
output = embedded
output, (hidden, cell) = self.lstm(output, (hidden, cell))
return output, (hidden, cell)
def init_hidden(self):
"""Init hidden
Returns:
hidden:
cell:
"""
cell = torch.zeros(1, 1, self.hidden_size, device=device)
hidden = torch.zeros(1, 1, self.hidden_size, device=device)
return hidden, cell
1.1.2 The Decoder
The decoder is another LSTM that takes the encoder output vector(s) and outputs a sequence of words to create the translation.
In the simplest seq2seq decoder we use only last output of the encoder.
This last output is sometimes called the context vector as it encodes context from the entire sequence.
This context vector is used as the initial hidden state of the decoder.
At every step of decoding, the decoder is given an input token and hidden state.
The initial input token is the start-of-string
class DecoderLSTM(nn.Module):
"""Decoder use LSTM as backbone"""
def __init__(self, hidden_size: int, output_size: int):
"""
Args:
hidden_size: The number of features in the hidden state
output_size : The number of expected features in the output
"""
super(DecoderLSTM, self).__init__()
self.hidden_size = hidden_size
# Retrieve word embeddings with dimentionality hidden_size
# using indices with dimentionality input_size, embeddding is learnable
# After embedding, input vector with input_size would be converted to hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
# LSTM
self.lstm = nn.LSTM(hidden_size, hidden_size)
# out
self.out = nn.Linear(hidden_size, output_size)
# log after softmax
self.log_softmax = nn.LogSoftmax(dim=1)
# activation function
self.activation_function = F.relu
def forward(self, inputs, state):
"""Forward
Args:
inputs: [1, hidden_size]
state : ([1, 1, hidden_size], [1, 1, hidden_size])
Returns:
output:
state: (hidden, cell)
"""
(hidden, cell) = state
# Retrieve word embeddings, [1, 1, hidden_size]
output = self.embedding(inputs).view(1, 1, -1)
# activation function, [1, 1, hidden_size]
output = self.activation_function(output)
# output: [1, 1, hidden_size]
output, (hidden, cell) = self.lstm(output, (hidden, cell))
# output: [output_size]
output = self.log_softmax(self.out(output[0]))
return output, (hidden, cell)
def init_hidden(self):
"""Init hidden
Returns:
hidden:
cell:
"""
cell = torch.zeros(1, 1, self.hidden_size, device=device)
hidden = torch.zeros(1, 1, self.hidden_size, device=device)
return hidden, cell
1.1.3 Train and Evaluate
def train_by_sentence(input_tensor, target_tensor, encoder, decoder,
encoder_optimizer, decoder_optimizer, loss_fn,
use_teacher_forcing=True, reverse_source_sentence=True,
max_length=MAX_LENGTH):
"""Train by single sentence using EncoderLSTM and DecoderLSTM
including training and update model
Args:
input_tensor: [input_sequence_len, 1, hidden_size]
target_tensor: [target_sequence_len, 1, hidden_size]
encoder: EncoderLSTM
decoder: DecoderLSTM
encoder_optimizer: optimizer for encoder
decoder_optimizer: optimizer for decoder
loss_fn: loss function
use_teacher_forcing: True is to Feed the target as the next input,
False is to use its own predictions as the next input
max_length: max length for input and output
Returns:
loss: scalar
"""
if reverse_source_sentence:
input_tensor = torch.flip(input_tensor, [0])
hidden, cell = encoder.init_hidden()
# Clears the gradients of all optimized torch.Tensors'
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
# Get sequence length of the input and target sentences.
input_length = input_tensor.size(0)
target_length = target_tensor.size(0)
# encoder outputs: [max_length, hidden_size]
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
loss = 0
# Get encoder outputs
for ei in range(input_length):
encoder_output, (hidden, cell) = encoder(
input_tensor[ei], (hidden, cell))
encoder_outputs[ei] = encoder_output[0, 0]
# First input for the decoder
decoder_input = torch.tensor([[SOS_token]], device=device)
# Last state of encoder as the init state of decoder
decoder_hidden = (hidden, cell)
for di in range(target_length):
decoder_output, (hidden, cell) = decoder(
decoder_input, (hidden, cell))
if use_teacher_forcing:
# Feed the target as the next input
loss += loss_fn(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # Teacher forcing
else:
# Use its own predictions as the next input
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach()
loss += loss_fn(decoder_output, target_tensor[di])
# End if decoder output End of Signal(EOS)
if decoder_input.item() == EOS_token:
break
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / target_length
def train(encoder, decoder, n_iters, reverse_source_sentence=True,
use_teacher_forcing=True,
print_every=1000, plot_every=100,
learning_rate=0.01):
"""Train of Seq2seq
Args:
encoder: EncoderLSTM
decoder: DecoderLSTM
n_iters: train with n_iters sentences without replacement
reverse_source_sentence: True is to reverse the source sentence
but keep order of target unchanged,
False is to keep order of the source sentence
target unchanged
use_teacher_forcing: True is to Feed the target as the next input,
False is to use its own predictions as the next input
print_every: print log every print_every
plot_every: plot every plot_every
learning_rate:
"""
start = time.time()
plot_losses = []
print_loss_total = 0
plot_loss_total = 0
# Use SGD to optimize encoder and decoder parameters
encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate)
# Obtain training input
training_pairs = [tensor_from_pair(random.choice(pairs), input_lang, output_lang)
for _ in range(n_iters)]
# Negative log likelihood loss
loss_fn = nn.NLLLoss()
for i in range(1, n_iters+1):
# Get a pair of sentences and move them to device,
# training_pair: ([Seq_size, 1, input_size], [Seq_size, 1, input_size])
training_pair = training_pairs[i-1]
input_tensor = training_pair[0].to(device)
target_tensor = training_pair[1].to(device)
# Train by a pair of source sentence and target sentence
loss = train_by_sentence(input_tensor, target_tensor,
encoder, decoder,
encoder_optimizer, decoder_optimizer,
loss_fn, use_teacher_forcing=use_teacher_forcing,
reverse_source_sentence=reverse_source_sentence)
print_loss_total += loss
plot_loss_total += loss
if i % print_every == 0:
# Print Loss
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print("%s (%d %d%%) %.4f" % (time_since(start, i / n_iters),
i, i / n_iters * 100, print_loss_avg))
if i % plot_every == 0:
# Plot
plot_loss_avg = plot_loss_total / plot_every
plot_losses.append(plot_loss_avg)
plot_loss_total = 0
# show plot
show_plot(plot_losses)
def evaluate_by_sentence(encoder, decoder, sentence, reverse_source_sentence, max_length=MAX_LENGTH):
"""Evalutae on a source sentence
Args:
encoder
decoder
sentence
max_length
Return:
decoded_words: predicted sentence
"""
with torch.no_grad():
# Get tensor of sentence
input_tensor = tensor_from_sentence(input_lang, sentence).to(device)
input_length = input_tensor.size(0)
if reverse_source_sentence:
input_tensor = torch.flip(input_tensor, [0])
# init state for encoder
(hidden, cell) = encoder.init_hidden()
# encoder outputs: [max_length, hidden_size]
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
for ei in range(input_length):
encoder_output, (hidden, cell) = encoder(input_tensor[ei],
(hidden, cell))
encoder_outputs[ei] += encoder_output[0, 0]
# Last state of encoder as the init state of decoder
decoder_input = torch.tensor([[SOS_token]], device=device)
decoder_hidden = (hidden, cell)
decoded_words = []
# When evaluate, use its own predictions as the next input
for di in range(max_length):
decoder_output, (hidden, cell) = decoder(decoder_input, (hidden, cell))
topv, topi = decoder_output.data.topk(1)
if topi.item() == EOS_token:
decoded_words.append("<EOS>")
break
else:
decoded_words.append(output_lang.index2word[topi.item()])
decoder_input = topi.squeeze().detach()
return decoded_words
def evaluate_randomly(encoder, decoder, n=10, reverse_source_sentence=True):
"""Random pick sentence from dataset and observe the effect of translation
Args:
encoder:
decoder:
n: numbers of sentences to evaluate
"""
for _ in range(n):
pair = random.choice(pairs)
# Source sentence
print(">", pair[0])
# Target sentence
print("=", pair[1])
output_words = evaluate_by_sentence(encoder, decoder, pair[0], reverse_source_sentence)
output_sentence = " ".join(output_words)
# Predicted sentence
print("<", output_sentence)
print("")
def show_plot(points):
"""Plot according to points"""
plt.figure()
fig, ax = plt.subplots()
loc = ticker.MultipleLocator(base=0.2)
ax.yaxis.set_major_locator(loc)
plt.plot(points)
plt.show()
1.1.4 Let’s load data and train
Using prepare_data function to obtain sentences as pairs (source sentence, target sentence).
# prepare_data defined in utis.py
# reverse to True here means, source sentence is English,
# while target sentence is France
input_lang, output_lang, pairs = prepare_data('eng', 'fra', reverse=True)
print(random.choice(pairs))
Reading lines...
Read 135842 sentence pairs
Reverse source sentence
Trimmed to 10599 sentence pairs
Counting words ...
Counting words:
fra 4345
eng 2803
['je suis d accord avec cette proposition .', 'i am in favor of the proposition .']
setup_seed(45)
hidden_size = 256
# Reverse the order of source input sentence
reverse_source_sentence = True
# Feed the target as the next input
use_teacher_forcing = True
encoder = EncoderLSTM(input_lang.n_words, hidden_size).to(device)
decoder = DecoderLSTM(hidden_size, output_lang.n_words).to(device)
print(">> Model is on: {}".format(next(encoder.parameters()).is_cuda))
print(">> Model is on: {}".format(next(decoder.parameters()).is_cuda))
>> Model is on: True
>> Model is on: True
iters = 50000
train(encoder, decoder, iters, reverse_source_sentence=reverse_source_sentence,
use_teacher_forcing=use_teacher_forcing,print_every=250, plot_every=250)
0m 10s (- 33m 33s) (250 0%) 4.7301
0m 18s (- 30m 34s) (500 1%) 3.3269
0m 26s (- 29m 3s) (750 1%) 3.0458
0m 34s (- 28m 30s) (1000 2%) 2.8595
0m 44s (- 29m 13s) (1250 2%) 2.8384
0m 55s (- 29m 40s) (1500 3%) 2.7370
1m 3s (- 29m 14s) (1750 3%) 2.6759
1m 12s (- 29m 0s) (2000 4%) 2.6775
1m 21s (- 28m 49s) (2250 4%) 2.6329
1m 30s (- 28m 41s) (2500 5%) 2.6113
1m 39s (- 28m 34s) (2750 5%) 2.5890
1m 48s (- 28m 23s) (3000 6%) 2.5076
1m 57s (- 28m 13s) (3250 6%) 2.4959
2m 6s (- 28m 5s) (3500 7%) 2.5263
2m 16s (- 27m 59s) (3750 7%) 2.5167
2m 25s (- 27m 57s) (4000 8%) 2.3970
2m 36s (- 28m 1s) (4250 8%) 2.4132
2m 46s (- 28m 0s) (4500 9%) 2.3209
2m 56s (- 28m 2s) (4750 9%) 2.2764
3m 6s (- 28m 2s) (5000 10%) 2.2885
3m 17s (- 28m 0s) (5250 10%) 2.3332
3m 27s (- 28m 0s) (5500 11%) 2.3204
3m 37s (- 27m 56s) (5750 11%) 2.2541
3m 48s (- 27m 53s) (6000 12%) 2.2727
3m 58s (- 27m 49s) (6250 12%) 2.2329
4m 8s (- 27m 43s) (6500 13%) 2.1703
4m 17s (- 27m 28s) (6750 13%) 2.0671
4m 27s (- 27m 20s) (7000 14%) 2.1644
4m 40s (- 27m 34s) (7250 14%) 2.2096
4m 50s (- 27m 25s) (7500 15%) 2.0804
5m 2s (- 27m 27s) (7750 15%) 2.1003
5m 15s (- 27m 33s) (8000 16%) 2.0653
5m 27s (- 27m 35s) (8250 16%) 2.0542
5m 39s (- 27m 35s) (8500 17%) 2.0976
5m 50s (- 27m 34s) (8750 17%) 2.0354
6m 2s (- 27m 32s) (9000 18%) 2.0289
6m 14s (- 27m 29s) (9250 18%) 1.9037
6m 25s (- 27m 25s) (9500 19%) 1.9525
6m 37s (- 27m 19s) (9750 19%) 1.8598
6m 48s (- 27m 14s) (10000 20%) 1.9433
7m 0s (- 27m 10s) (10250 20%) 1.9164
7m 12s (- 27m 6s) (10500 21%) 1.8676
7m 23s (- 26m 59s) (10750 21%) 1.8912
7m 34s (- 26m 50s) (11000 22%) 1.8940
7m 44s (- 26m 38s) (11250 22%) 1.8391
7m 54s (- 26m 28s) (11500 23%) 1.9038
8m 4s (- 26m 18s) (11750 23%) 1.8223
8m 15s (- 26m 10s) (12000 24%) 1.7111
8m 28s (- 26m 5s) (12250 24%) 1.8238
8m 41s (- 26m 5s) (12500 25%) 1.7750
8m 57s (- 26m 9s) (12750 25%) 1.8930
9m 6s (- 25m 54s) (13000 26%) 1.7776
9m 17s (- 25m 45s) (13250 26%) 1.7633
9m 27s (- 25m 35s) (13500 27%) 1.7333
9m 40s (- 25m 29s) (13750 27%) 1.7893
9m 54s (- 25m 28s) (14000 28%) 1.7390
10m 5s (- 25m 18s) (14250 28%) 1.7701
10m 16s (- 25m 9s) (14500 28%) 1.7329
10m 31s (- 25m 10s) (14750 29%) 1.6696
10m 44s (- 25m 3s) (15000 30%) 1.6313
10m 59s (- 25m 2s) (15250 30%) 1.7256
11m 12s (- 24m 56s) (15500 31%) 1.6859
11m 24s (- 24m 49s) (15750 31%) 1.6195
11m 38s (- 24m 45s) (16000 32%) 1.5513
11m 52s (- 24m 39s) (16250 32%) 1.6846
12m 4s (- 24m 31s) (16500 33%) 1.6875
12m 16s (- 24m 21s) (16750 33%) 1.5778
12m 27s (- 24m 11s) (17000 34%) 1.6210
12m 38s (- 24m 0s) (17250 34%) 1.5758
12m 50s (- 23m 50s) (17500 35%) 1.5593
13m 1s (- 23m 40s) (17750 35%) 1.5810
13m 13s (- 23m 31s) (18000 36%) 1.5944
13m 25s (- 23m 22s) (18250 36%) 1.5053
13m 36s (- 23m 10s) (18500 37%) 1.4108
13m 48s (- 23m 0s) (18750 37%) 1.5082
14m 0s (- 22m 50s) (19000 38%) 1.5458
14m 12s (- 22m 41s) (19250 38%) 1.4254
14m 23s (- 22m 30s) (19500 39%) 1.4709
14m 35s (- 22m 20s) (19750 39%) 1.4742
14m 46s (- 22m 9s) (20000 40%) 1.3979
14m 57s (- 21m 58s) (20250 40%) 1.4668
15m 9s (- 21m 48s) (20500 41%) 1.4649
15m 20s (- 21m 37s) (20750 41%) 1.4709
15m 31s (- 21m 26s) (21000 42%) 1.4918
15m 42s (- 21m 15s) (21250 42%) 1.4107
15m 53s (- 21m 4s) (21500 43%) 1.4762
16m 5s (- 20m 53s) (21750 43%) 1.5225
16m 16s (- 20m 42s) (22000 44%) 1.4054
16m 27s (- 20m 31s) (22250 44%) 1.3352
16m 40s (- 20m 23s) (22500 45%) 1.3740
16m 57s (- 20m 18s) (22750 45%) 1.4333
17m 10s (- 20m 10s) (23000 46%) 1.3943
17m 25s (- 20m 3s) (23250 46%) 1.2736
17m 39s (- 19m 55s) (23500 47%) 1.3318
17m 54s (- 19m 47s) (23750 47%) 1.3693
18m 8s (- 19m 38s) (24000 48%) 1.3522
18m 24s (- 19m 32s) (24250 48%) 1.2736
18m 38s (- 19m 23s) (24500 49%) 1.3980
18m 52s (- 19m 15s) (24750 49%) 1.2201
19m 5s (- 19m 5s) (25000 50%) 1.2675
19m 21s (- 18m 58s) (25250 50%) 1.3469
19m 37s (- 18m 51s) (25500 51%) 1.2714
19m 53s (- 18m 43s) (25750 51%) 1.2665
20m 7s (- 18m 34s) (26000 52%) 1.2653
20m 21s (- 18m 24s) (26250 52%) 1.1929
20m 35s (- 18m 15s) (26500 53%) 1.2523
20m 48s (- 18m 5s) (26750 53%) 1.2691
21m 3s (- 17m 56s) (27000 54%) 1.1528
21m 18s (- 17m 47s) (27250 54%) 1.2370
21m 33s (- 17m 38s) (27500 55%) 1.2660
21m 48s (- 17m 29s) (27750 55%) 1.2506
22m 3s (- 17m 19s) (28000 56%) 1.2735
22m 16s (- 17m 8s) (28250 56%) 1.2148
22m 30s (- 16m 58s) (28500 56%) 1.2847
22m 43s (- 16m 47s) (28750 57%) 1.2118
22m 58s (- 16m 38s) (29000 57%) 1.1789
23m 12s (- 16m 28s) (29250 58%) 1.1460
23m 24s (- 16m 16s) (29500 59%) 1.1338
23m 40s (- 16m 6s) (29750 59%) 1.1070
23m 57s (- 15m 58s) (30000 60%) 1.2129
24m 12s (- 15m 48s) (30250 60%) 1.0972
24m 28s (- 15m 39s) (30500 61%) 1.0851
24m 40s (- 15m 26s) (30750 61%) 1.1832
24m 52s (- 15m 14s) (31000 62%) 1.0532
25m 5s (- 15m 3s) (31250 62%) 1.1463
25m 19s (- 14m 52s) (31500 63%) 1.0433
25m 32s (- 14m 40s) (31750 63%) 1.0821
25m 48s (- 14m 30s) (32000 64%) 1.0334
26m 3s (- 14m 20s) (32250 64%) 1.1181
26m 14s (- 14m 7s) (32500 65%) 1.1509
26m 28s (- 13m 56s) (32750 65%) 1.1036
26m 43s (- 13m 45s) (33000 66%) 1.0277
26m 54s (- 13m 33s) (33250 66%) 1.1785
27m 8s (- 13m 21s) (33500 67%) 1.0550
27m 22s (- 13m 10s) (33750 67%) 1.0629
27m 37s (- 13m 0s) (34000 68%) 1.0696
27m 57s (- 12m 51s) (34250 68%) 1.0918
28m 9s (- 12m 39s) (34500 69%) 1.0613
28m 22s (- 12m 27s) (34750 69%) 1.0352
28m 35s (- 12m 15s) (35000 70%) 1.0065
28m 50s (- 12m 3s) (35250 70%) 1.0674
29m 4s (- 11m 52s) (35500 71%) 1.0631
29m 19s (- 11m 41s) (35750 71%) 1.1001
29m 33s (- 11m 29s) (36000 72%) 1.0393
29m 48s (- 11m 18s) (36250 72%) 0.9400
30m 3s (- 11m 7s) (36500 73%) 1.0264
30m 18s (- 10m 55s) (36750 73%) 0.9909
30m 32s (- 10m 43s) (37000 74%) 0.9877
30m 45s (- 10m 31s) (37250 74%) 0.9790
31m 0s (- 10m 20s) (37500 75%) 0.8614
31m 15s (- 10m 8s) (37750 75%) 0.8985
31m 29s (- 9m 56s) (38000 76%) 0.9313
31m 44s (- 9m 45s) (38250 76%) 0.9810
31m 58s (- 9m 32s) (38500 77%) 0.8965
32m 12s (- 9m 21s) (38750 77%) 0.9325
32m 26s (- 9m 9s) (39000 78%) 0.9488
32m 41s (- 8m 57s) (39250 78%) 0.8820
32m 57s (- 8m 45s) (39500 79%) 0.9141
33m 11s (- 8m 33s) (39750 79%) 0.9451
33m 24s (- 8m 21s) (40000 80%) 0.8610
33m 37s (- 8m 8s) (40250 80%) 0.8987
33m 52s (- 7m 56s) (40500 81%) 0.9370
34m 6s (- 7m 44s) (40750 81%) 0.9663
34m 20s (- 7m 32s) (41000 82%) 0.8364
34m 33s (- 7m 19s) (41250 82%) 0.9296
34m 48s (- 7m 7s) (41500 83%) 0.8876
35m 2s (- 6m 55s) (41750 83%) 0.7837
35m 15s (- 6m 42s) (42000 84%) 0.8643
35m 27s (- 6m 30s) (42250 84%) 0.9092
35m 40s (- 6m 17s) (42500 85%) 0.8111
35m 53s (- 6m 5s) (42750 85%) 0.8668
36m 5s (- 5m 52s) (43000 86%) 0.8687
36m 19s (- 5m 40s) (43250 86%) 0.8701
36m 31s (- 5m 27s) (43500 87%) 0.8108
36m 42s (- 5m 14s) (43750 87%) 0.7329
36m 53s (- 5m 1s) (44000 88%) 0.8410
37m 5s (- 4m 49s) (44250 88%) 0.8041
37m 16s (- 4m 36s) (44500 89%) 0.7772
37m 26s (- 4m 23s) (44750 89%) 0.8702
37m 38s (- 4m 10s) (45000 90%) 0.8274
37m 50s (- 3m 58s) (45250 90%) 0.7602
38m 1s (- 3m 45s) (45500 91%) 0.8276
38m 13s (- 3m 33s) (45750 91%) 0.7752
38m 24s (- 3m 20s) (46000 92%) 0.7822
38m 34s (- 3m 7s) (46250 92%) 0.7470
38m 47s (- 2m 55s) (46500 93%) 0.7725
38m 59s (- 2m 42s) (46750 93%) 0.7477
39m 12s (- 2m 30s) (47000 94%) 0.7231
39m 25s (- 2m 17s) (47250 94%) 0.7538
39m 38s (- 2m 5s) (47500 95%) 0.8537
39m 49s (- 1m 52s) (47750 95%) 0.7798
40m 1s (- 1m 40s) (48000 96%) 0.7322
40m 13s (- 1m 27s) (48250 96%) 0.8085
40m 24s (- 1m 14s) (48500 97%) 0.7098
40m 36s (- 1m 2s) (48750 97%) 0.7215
40m 48s (- 0m 49s) (49000 98%) 0.8122
41m 1s (- 0m 37s) (49250 98%) 0.7791
41m 12s (- 0m 24s) (49500 99%) 0.7251
41m 24s (- 0m 12s) (49750 99%) 0.7874
41m 33s (- 0m 0s) (50000 100%) 0.7124
<Figure size 432x288 with 0 Axes>

# Randomly pick up 10 sentence and observe the performance
evaluate_randomly(encoder, decoder, 10, reverse_source_sentence)
> je suis tres fier de nos etudiants .
= i m very proud of our students .
< i m very proud of you . <EOS>
> vous etes faibles .
= you re weak .
< you re rude . <EOS>
> tu n es pas si vieux .
= you re not that old .
< you re not that old . <EOS>
> je songe a demissionner immediatement .
= i am thinking of resigning at once .
< i m thinking about the problem . <EOS>
> je suis en retard sur le programme .
= i m behind schedule .
< i m behind schedule . <EOS>
> je suis submerge de travail .
= i m swamped with work .
< i m proud of that . <EOS>
> je ne vais pas prendre le moindre risque .
= i m not taking any chances .
< i m not taking any chances . <EOS>
> je suis au restaurant .
= i m at the restaurant .
< i m in the office . <EOS>
> c est toi la doyenne .
= you re the oldest .
< you re the oldest . <EOS>
> je suis tres reconnaissant pour votre aide .
= i m very grateful for your help .
< i m very worried about you . <EOS>
作业-1
-
注意到,Seq2seq的论文中,input sentence的输入是逆序的,实际上本实验课也是如此。 按照论文的说法,如果是input sentence是顺序的,模型在同等条件下应该收敛速度可能会更慢。 请运行 train 去检验该想法。 (Hint: reverse_source_sentence 控制source sentence是否是逆序输入)
- When
reverse_source_sentence=True, (i.e., the sentence is input reversely), the loss plot is shown as follows: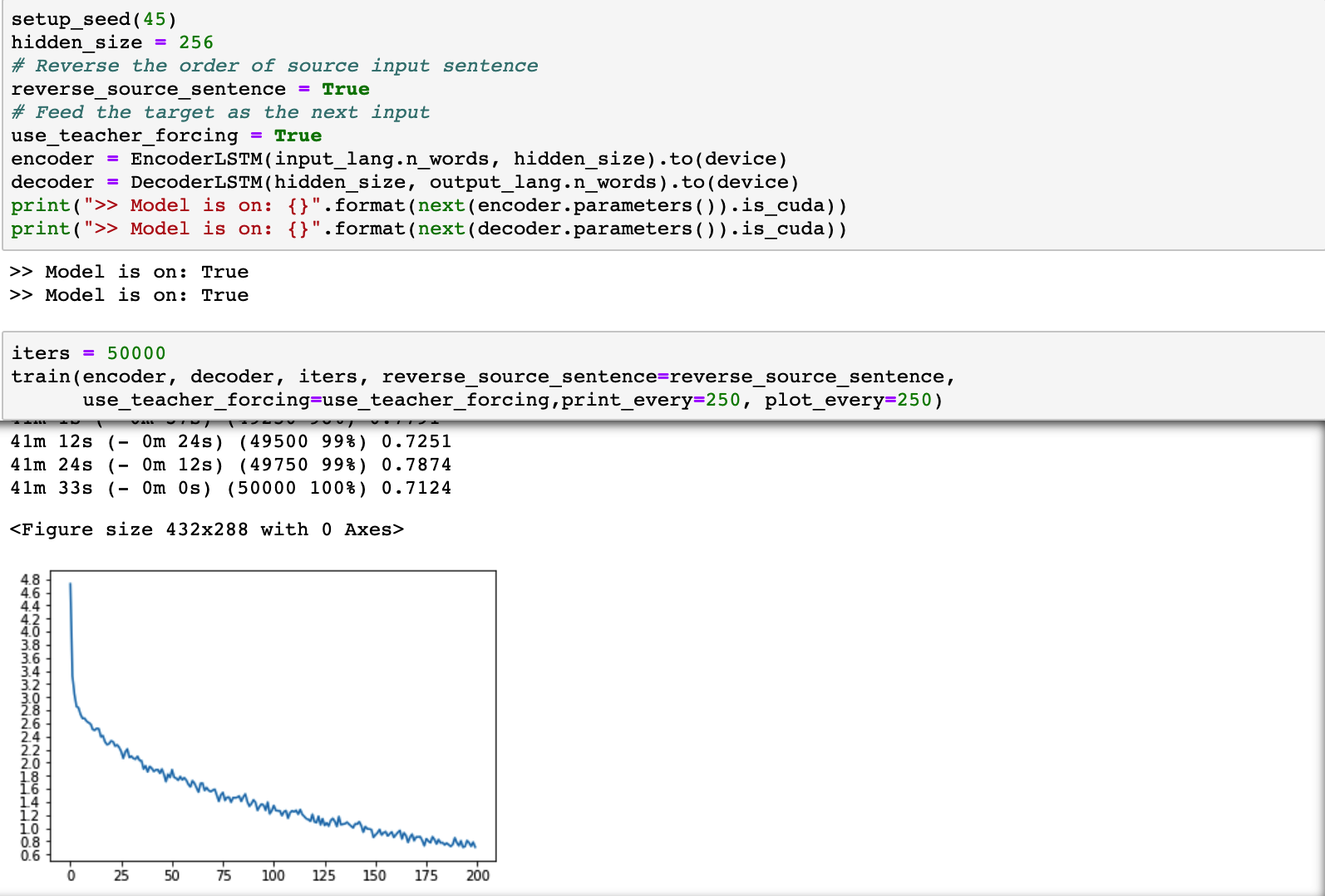
- When
reverse_source_sentence=False, (i.e., the sentence is input in order), the loss plot is shown as follows: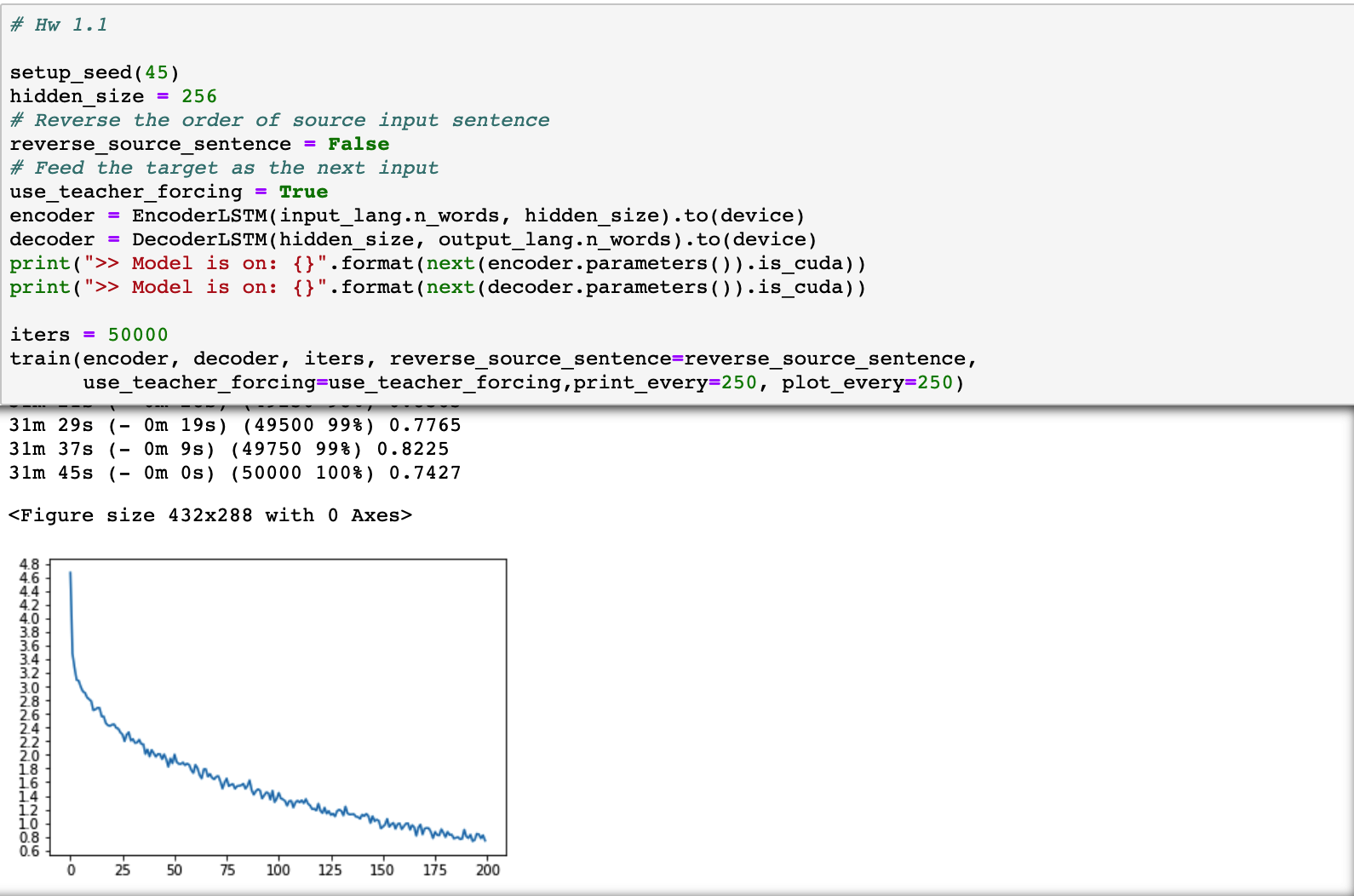
Note that the convergence speeda are almost the same when input in order. So the argument doesn’t stand on points in this work.
- When
-
注意到, 该课件decoder的输入,既可以是来自于targer sentence也可以是是来自于上一个时刻 decoder的output。请运行 train 去看看有什么差别 (Hint: reverse_source_sentence 控制source sentence是否是逆序输入)
- When
use_teacher_forcing=True, (i.e., the input of decoder is from the target sentence), the loss plot is shown as follows: - When
use_teacher_forcing=False, (i.e., the input of decoder is from the decoder’s output of the last moment), the loss plot is shown as follows: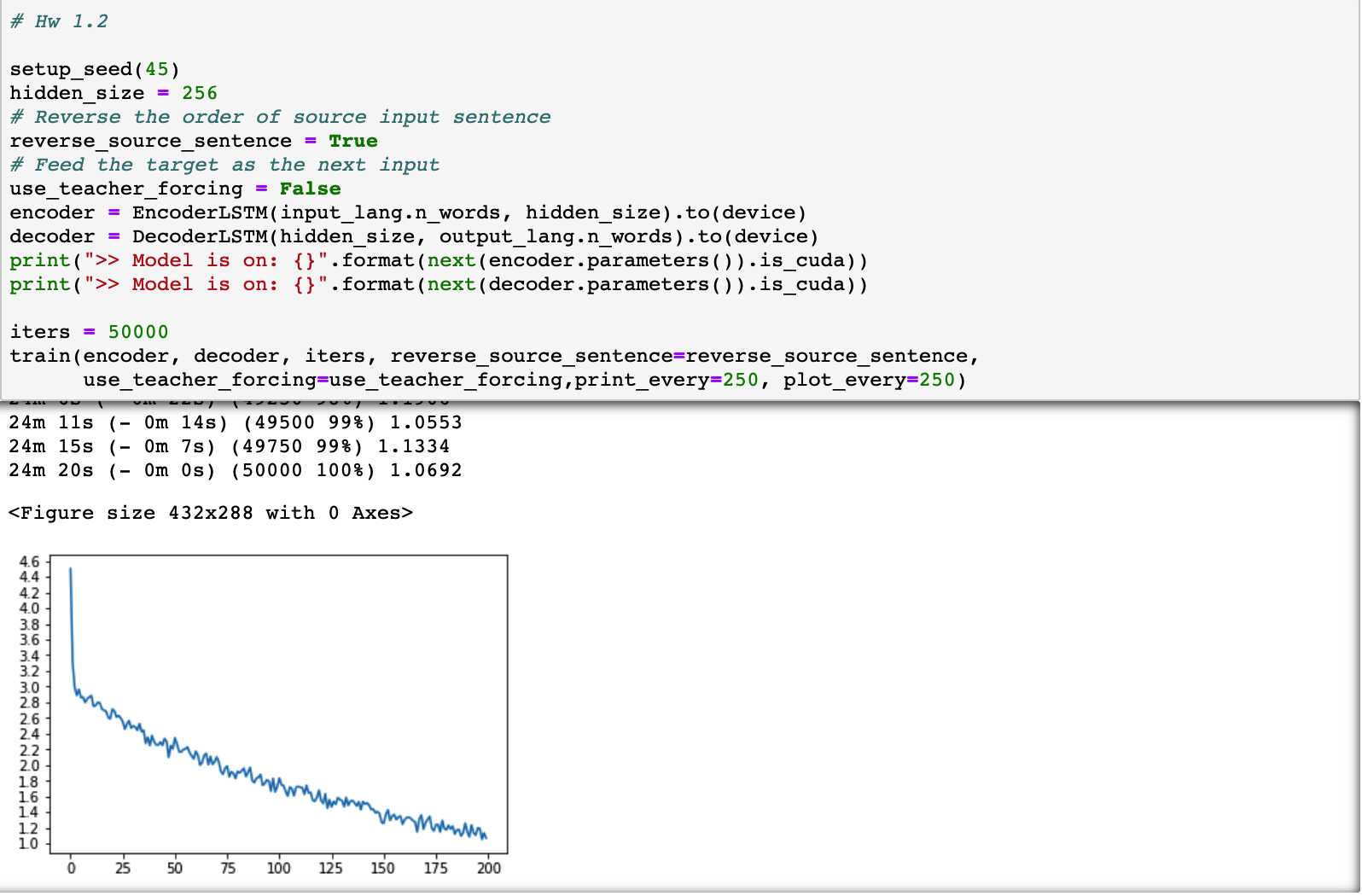
Note that the convergence speed is longer when from the output of last moment, and the loss decrease when from the target sentenses is more steer.
- When
-
实际上decoder的激活函数除了relu,还可以选用tanh,请改变decoder的激活函数并且运行 train。
- When
DecoderLSTM_v2.activation_function = torch.relu, (i.e., the activation function is relu), the loss plot is shown as follows: - When
DecoderLSTM_v2.activation_function = torch.tahn, (i.e., the activation function is tahn), the loss plot is shown as follows:
Note that the convergence speed is faster in the early time period when using relu, but sooner the two come to the same position.
- When
# Hw 1.1
setup_seed(45)
hidden_size = 256
# Reverse the order of source input sentence
reverse_source_sentence = False
# Feed the target as the next input
use_teacher_forcing = True
encoder = EncoderLSTM(input_lang.n_words, hidden_size).to(device)
decoder = DecoderLSTM(hidden_size, output_lang.n_words).to(device)
print(">> Model is on: {}".format(next(encoder.parameters()).is_cuda))
print(">> Model is on: {}".format(next(decoder.parameters()).is_cuda))
iters = 50000
train(encoder, decoder, iters, reverse_source_sentence=reverse_source_sentence,
use_teacher_forcing=use_teacher_forcing,print_every=250, plot_every=250)
>> Model is on: True
>> Model is on: True
0m 14s (- 48m 0s) (250 0%) 4.6714
0m 24s (- 39m 46s) (500 1%) 3.4858
0m 36s (- 39m 59s) (750 1%) 3.2751
0m 48s (- 39m 36s) (1000 2%) 3.0976
0m 57s (- 37m 9s) (1250 2%) 3.0855
1m 7s (- 36m 10s) (1500 3%) 2.9952
1m 15s (- 34m 37s) (1750 3%) 2.9293
1m 25s (- 34m 21s) (2000 4%) 2.9101
1m 39s (- 35m 2s) (2250 4%) 2.8425
1m 48s (- 34m 30s) (2500 5%) 2.8138
1m 56s (- 33m 27s) (2750 5%) 2.7875
2m 8s (- 33m 32s) (3000 6%) 2.6527
2m 22s (- 34m 11s) (3250 6%) 2.6663
2m 34s (- 34m 8s) (3500 7%) 2.6896
2m 44s (- 33m 48s) (3750 7%) 2.6877
2m 54s (- 33m 22s) (4000 8%) 2.5639
3m 3s (- 32m 57s) (4250 8%) 2.5633
3m 14s (- 32m 46s) (4500 9%) 2.4649
3m 24s (- 32m 30s) (4750 9%) 2.4340
3m 34s (- 32m 13s) (5000 10%) 2.4237
3m 44s (- 31m 56s) (5250 10%) 2.4428
3m 53s (- 31m 31s) (5500 11%) 2.4482
4m 5s (- 31m 30s) (5750 11%) 2.3957
4m 15s (- 31m 12s) (6000 12%) 2.3834
4m 26s (- 31m 3s) (6250 12%) 2.3281
4m 36s (- 30m 53s) (6500 13%) 2.2984
4m 47s (- 30m 41s) (6750 13%) 2.2002
4m 58s (- 30m 33s) (7000 14%) 2.2964
5m 10s (- 30m 29s) (7250 14%) 2.3317
5m 22s (- 30m 28s) (7500 15%) 2.2087
5m 34s (- 30m 22s) (7750 15%) 2.2318
5m 44s (- 30m 6s) (8000 16%) 2.1741
5m 55s (- 29m 59s) (8250 16%) 2.1802
6m 7s (- 29m 54s) (8500 17%) 2.2237
6m 18s (- 29m 44s) (8750 17%) 2.1596
6m 30s (- 29m 38s) (9000 18%) 2.1561
6m 41s (- 29m 29s) (9250 18%) 2.0127
6m 53s (- 29m 23s) (9500 19%) 2.0805
7m 3s (- 29m 8s) (9750 19%) 1.9760
7m 15s (- 29m 1s) (10000 20%) 2.0731
7m 24s (- 28m 44s) (10250 20%) 2.0243
7m 35s (- 28m 35s) (10500 21%) 1.9722
7m 44s (- 28m 17s) (10750 21%) 2.0133
7m 53s (- 27m 59s) (11000 22%) 2.0114
8m 5s (- 27m 51s) (11250 22%) 1.9371
8m 15s (- 27m 39s) (11500 23%) 2.0084
8m 27s (- 27m 32s) (11750 23%) 1.9365
8m 39s (- 27m 23s) (12000 24%) 1.8248
8m 50s (- 27m 13s) (12250 24%) 1.9471
8m 59s (- 26m 59s) (12500 25%) 1.8760
9m 9s (- 26m 46s) (12750 25%) 2.0061
9m 20s (- 26m 34s) (13000 26%) 1.8975
9m 33s (- 26m 31s) (13250 26%) 1.8681
9m 44s (- 26m 19s) (13500 27%) 1.8666
9m 55s (- 26m 10s) (13750 27%) 1.8889
10m 7s (- 26m 1s) (14000 28%) 1.8494
10m 18s (- 25m 52s) (14250 28%) 1.8718
10m 29s (- 25m 40s) (14500 28%) 1.8546
10m 41s (- 25m 34s) (14750 29%) 1.7775
10m 52s (- 25m 21s) (15000 30%) 1.7341
11m 2s (- 25m 10s) (15250 30%) 1.8543
11m 13s (- 24m 58s) (15500 31%) 1.8051
11m 22s (- 24m 43s) (15750 31%) 1.7052
11m 31s (- 24m 28s) (16000 32%) 1.6546
11m 40s (- 24m 14s) (16250 32%) 1.7894
11m 49s (- 24m 0s) (16500 33%) 1.7909
11m 58s (- 23m 47s) (16750 33%) 1.6812
12m 8s (- 23m 33s) (17000 34%) 1.7208
12m 17s (- 23m 19s) (17250 34%) 1.6634
12m 25s (- 23m 4s) (17500 35%) 1.6423
12m 33s (- 22m 48s) (17750 35%) 1.6812
12m 42s (- 22m 36s) (18000 36%) 1.6888
12m 53s (- 22m 25s) (18250 36%) 1.6100
13m 2s (- 22m 12s) (18500 37%) 1.5059
13m 11s (- 21m 58s) (18750 37%) 1.5959
13m 20s (- 21m 45s) (19000 38%) 1.6546
13m 29s (- 21m 32s) (19250 38%) 1.5423
13m 37s (- 21m 19s) (19500 39%) 1.5616
13m 46s (- 21m 6s) (19750 39%) 1.5739
13m 55s (- 20m 53s) (20000 40%) 1.5041
14m 4s (- 20m 41s) (20250 40%) 1.5423
14m 14s (- 20m 30s) (20500 41%) 1.5468
14m 23s (- 20m 17s) (20750 41%) 1.5539
14m 32s (- 20m 4s) (21000 42%) 1.5784
14m 41s (- 19m 52s) (21250 42%) 1.5044
14m 50s (- 19m 40s) (21500 43%) 1.5461
14m 59s (- 19m 28s) (21750 43%) 1.6279
15m 7s (- 19m 15s) (22000 44%) 1.4824
15m 17s (- 19m 4s) (22250 44%) 1.4165
15m 26s (- 18m 52s) (22500 45%) 1.4686
15m 35s (- 18m 40s) (22750 45%) 1.4966
15m 45s (- 18m 29s) (23000 46%) 1.4789
15m 52s (- 18m 16s) (23250 46%) 1.3615
16m 0s (- 18m 3s) (23500 47%) 1.4052
16m 10s (- 17m 52s) (23750 47%) 1.4511
16m 20s (- 17m 42s) (24000 48%) 1.4402
16m 30s (- 17m 31s) (24250 48%) 1.3447
16m 38s (- 17m 19s) (24500 49%) 1.4752
16m 48s (- 17m 8s) (24750 49%) 1.3075
16m 57s (- 16m 57s) (25000 50%) 1.3571
17m 7s (- 16m 47s) (25250 50%) 1.4438
17m 16s (- 16m 35s) (25500 51%) 1.3615
17m 25s (- 16m 24s) (25750 51%) 1.3481
17m 34s (- 16m 13s) (26000 52%) 1.3252
17m 43s (- 16m 2s) (26250 52%) 1.2551
17m 52s (- 15m 51s) (26500 53%) 1.3232
18m 1s (- 15m 39s) (26750 53%) 1.3265
18m 9s (- 15m 28s) (27000 54%) 1.2293
18m 19s (- 15m 17s) (27250 54%) 1.3035
18m 28s (- 15m 7s) (27500 55%) 1.3292
18m 38s (- 14m 56s) (27750 55%) 1.3038
18m 46s (- 14m 45s) (28000 56%) 1.3342
18m 55s (- 14m 34s) (28250 56%) 1.2919
19m 4s (- 14m 23s) (28500 56%) 1.3521
19m 13s (- 14m 12s) (28750 57%) 1.2852
19m 22s (- 14m 2s) (29000 57%) 1.2585
19m 31s (- 13m 51s) (29250 58%) 1.2053
19m 40s (- 13m 40s) (29500 59%) 1.2100
19m 50s (- 13m 30s) (29750 59%) 1.1837
19m 58s (- 13m 19s) (30000 60%) 1.2855
20m 7s (- 13m 8s) (30250 60%) 1.1795
20m 17s (- 12m 58s) (30500 61%) 1.1474
20m 27s (- 12m 48s) (30750 61%) 1.2269
20m 36s (- 12m 37s) (31000 62%) 1.1390
20m 46s (- 12m 27s) (31250 62%) 1.1778
20m 55s (- 12m 17s) (31500 63%) 1.1195
21m 5s (- 12m 7s) (31750 63%) 1.1402
21m 14s (- 11m 56s) (32000 64%) 1.0976
21m 22s (- 11m 46s) (32250 64%) 1.1781
21m 33s (- 11m 36s) (32500 65%) 1.1969
21m 41s (- 11m 25s) (32750 65%) 1.1784
21m 50s (- 11m 15s) (33000 66%) 1.1126
22m 0s (- 11m 5s) (33250 66%) 1.2442
22m 10s (- 10m 55s) (33500 67%) 1.1424
22m 19s (- 10m 44s) (33750 67%) 1.1265
22m 29s (- 10m 35s) (34000 68%) 1.1299
22m 38s (- 10m 24s) (34250 68%) 1.1325
22m 48s (- 10m 14s) (34500 69%) 1.0950
22m 56s (- 10m 4s) (34750 69%) 1.0889
23m 5s (- 9m 53s) (35000 70%) 1.0644
23m 14s (- 9m 43s) (35250 70%) 1.1237
23m 23s (- 9m 33s) (35500 71%) 1.1032
23m 33s (- 9m 23s) (35750 71%) 1.1367
23m 42s (- 9m 13s) (36000 72%) 1.1039
23m 51s (- 9m 2s) (36250 72%) 1.0013
24m 0s (- 8m 52s) (36500 73%) 1.1018
24m 9s (- 8m 42s) (36750 73%) 1.0291
24m 18s (- 8m 32s) (37000 74%) 1.0513
24m 27s (- 8m 22s) (37250 74%) 1.0345
24m 36s (- 8m 12s) (37500 75%) 0.9229
24m 44s (- 8m 1s) (37750 75%) 0.9472
24m 53s (- 7m 51s) (38000 76%) 0.9795
25m 2s (- 7m 41s) (38250 76%) 1.0625
25m 10s (- 7m 31s) (38500 77%) 0.9455
25m 20s (- 7m 21s) (38750 77%) 0.9808
25m 28s (- 7m 11s) (39000 78%) 1.0044
25m 38s (- 7m 1s) (39250 78%) 0.9169
25m 47s (- 6m 51s) (39500 79%) 0.9849
25m 56s (- 6m 41s) (39750 79%) 0.9961
26m 5s (- 6m 31s) (40000 80%) 0.9106
26m 14s (- 6m 21s) (40250 80%) 0.9502
26m 22s (- 6m 11s) (40500 81%) 0.9925
26m 32s (- 6m 1s) (40750 81%) 0.9969
26m 41s (- 5m 51s) (41000 82%) 0.9025
26m 50s (- 5m 41s) (41250 82%) 0.9700
26m 59s (- 5m 31s) (41500 83%) 0.9398
27m 9s (- 5m 22s) (41750 83%) 0.8147
27m 18s (- 5m 12s) (42000 84%) 0.9346
27m 27s (- 5m 2s) (42250 84%) 0.9792
27m 36s (- 4m 52s) (42500 85%) 0.8348
27m 45s (- 4m 42s) (42750 85%) 0.9208
27m 54s (- 4m 32s) (43000 86%) 0.9285
28m 4s (- 4m 22s) (43250 86%) 0.9242
28m 13s (- 4m 13s) (43500 87%) 0.8695
28m 22s (- 4m 3s) (43750 87%) 0.7792
28m 32s (- 3m 53s) (44000 88%) 0.8718
28m 41s (- 3m 43s) (44250 88%) 0.8257
28m 50s (- 3m 33s) (44500 89%) 0.8202
29m 0s (- 3m 24s) (44750 89%) 0.9108
29m 8s (- 3m 14s) (45000 90%) 0.8588
29m 17s (- 3m 4s) (45250 90%) 0.7951
29m 24s (- 2m 54s) (45500 91%) 0.8723
29m 32s (- 2m 44s) (45750 91%) 0.8268
29m 40s (- 2m 34s) (46000 92%) 0.8319
29m 48s (- 2m 24s) (46250 92%) 0.7746
29m 55s (- 2m 15s) (46500 93%) 0.7857
30m 3s (- 2m 5s) (46750 93%) 0.7949
30m 11s (- 1m 55s) (47000 94%) 0.7646
30m 19s (- 1m 45s) (47250 94%) 0.7716
30m 26s (- 1m 36s) (47500 95%) 0.9043
30m 34s (- 1m 26s) (47750 95%) 0.8049
30m 42s (- 1m 16s) (48000 96%) 0.7793
30m 50s (- 1m 7s) (48250 96%) 0.8312
30m 58s (- 0m 57s) (48500 97%) 0.7354
31m 6s (- 0m 47s) (48750 97%) 0.7525
31m 13s (- 0m 38s) (49000 98%) 0.8443
31m 21s (- 0m 28s) (49250 98%) 0.8365
31m 29s (- 0m 19s) (49500 99%) 0.7765
31m 37s (- 0m 9s) (49750 99%) 0.8225
31m 45s (- 0m 0s) (50000 100%) 0.7427
<Figure size 432x288 with 0 Axes>

# Hw 1.2
setup_seed(45)
hidden_size = 256
# Reverse the order of source input sentence
reverse_source_sentence = True
# Feed the target as the next input
use_teacher_forcing = False
encoder = EncoderLSTM(input_lang.n_words, hidden_size).to(device)
decoder = DecoderLSTM(hidden_size, output_lang.n_words).to(device)
print(">> Model is on: {}".format(next(encoder.parameters()).is_cuda))
print(">> Model is on: {}".format(next(decoder.parameters()).is_cuda))
iters = 50000
train(encoder, decoder, iters, reverse_source_sentence=reverse_source_sentence,
use_teacher_forcing=use_teacher_forcing,print_every=250, plot_every=250)
>> Model is on: True
>> Model is on: True
0m 11s (- 39m 1s) (250 0%) 4.5025
0m 21s (- 35m 34s) (500 1%) 3.3029
0m 29s (- 32m 22s) (750 1%) 2.9893
0m 38s (- 31m 47s) (1000 2%) 2.8886
0m 48s (- 31m 16s) (1250 2%) 2.9643
1m 1s (- 33m 9s) (1500 3%) 2.8594
1m 13s (- 33m 50s) (1750 3%) 2.8643
1m 20s (- 32m 1s) (2000 4%) 2.7976
1m 26s (- 30m 39s) (2250 4%) 2.8458
1m 33s (- 29m 35s) (2500 5%) 2.8655
1m 40s (- 28m 39s) (2750 5%) 2.8859
1m 46s (- 27m 51s) (3000 6%) 2.7476
1m 53s (- 27m 12s) (3250 6%) 2.7577
2m 0s (- 26m 36s) (3500 7%) 2.7986
2m 6s (- 26m 2s) (3750 7%) 2.7935
2m 13s (- 25m 36s) (4000 8%) 2.7148
2m 20s (- 25m 9s) (4250 8%) 2.6984
2m 27s (- 24m 48s) (4500 9%) 2.6851
2m 37s (- 24m 57s) (4750 9%) 2.6087
2m 44s (- 24m 36s) (5000 10%) 2.5876
2m 50s (- 24m 17s) (5250 10%) 2.7120
2m 57s (- 23m 59s) (5500 11%) 2.6891
3m 4s (- 23m 43s) (5750 11%) 2.6112
3m 11s (- 23m 26s) (6000 12%) 2.6307
3m 18s (- 23m 10s) (6250 12%) 2.5999
3m 25s (- 22m 55s) (6500 13%) 2.5548
3m 32s (- 22m 40s) (6750 13%) 2.4575
3m 39s (- 22m 26s) (7000 14%) 2.5242
3m 46s (- 22m 13s) (7250 14%) 2.5643
3m 52s (- 22m 0s) (7500 15%) 2.4702
3m 59s (- 21m 46s) (7750 15%) 2.4989
4m 6s (- 21m 33s) (8000 16%) 2.4834
4m 16s (- 21m 38s) (8250 16%) 2.4431
4m 24s (- 21m 33s) (8500 17%) 2.5258
4m 32s (- 21m 25s) (8750 17%) 2.4261
4m 40s (- 21m 18s) (9000 18%) 2.4441
4m 48s (- 21m 11s) (9250 18%) 2.2770
4m 56s (- 21m 3s) (9500 19%) 2.3535
5m 6s (- 21m 6s) (9750 19%) 2.2491
5m 21s (- 21m 27s) (10000 20%) 2.3741
5m 35s (- 21m 42s) (10250 20%) 2.2997
5m 43s (- 21m 33s) (10500 21%) 2.2575
5m 51s (- 21m 24s) (10750 21%) 2.2566
5m 59s (- 21m 15s) (11000 22%) 2.2933
6m 7s (- 21m 5s) (11250 22%) 2.2505
6m 15s (- 20m 56s) (11500 23%) 2.3371
6m 23s (- 20m 48s) (11750 23%) 2.3011
6m 31s (- 20m 39s) (12000 24%) 2.0989
6m 39s (- 20m 30s) (12250 24%) 2.2465
6m 47s (- 20m 21s) (12500 25%) 2.2069
6m 54s (- 20m 12s) (12750 25%) 2.3457
7m 2s (- 20m 3s) (13000 26%) 2.2645
7m 10s (- 19m 55s) (13250 26%) 2.1701
7m 18s (- 19m 46s) (13500 27%) 2.1677
7m 26s (- 19m 38s) (13750 27%) 2.1980
7m 34s (- 19m 29s) (14000 28%) 2.2050
7m 42s (- 19m 21s) (14250 28%) 2.2295
7m 50s (- 19m 12s) (14500 28%) 2.1602
7m 58s (- 19m 4s) (14750 29%) 2.1159
8m 6s (- 18m 55s) (15000 30%) 2.0797
8m 14s (- 18m 47s) (15250 30%) 2.1747
8m 22s (- 18m 39s) (15500 31%) 2.1242
8m 30s (- 18m 30s) (15750 31%) 1.9999
8m 38s (- 18m 21s) (16000 32%) 2.0295
8m 46s (- 18m 13s) (16250 32%) 2.1235
8m 54s (- 18m 4s) (16500 33%) 2.1474
9m 2s (- 17m 56s) (16750 33%) 2.0056
9m 10s (- 17m 48s) (17000 34%) 2.1091
9m 18s (- 17m 39s) (17250 34%) 2.0094
9m 26s (- 17m 31s) (17500 35%) 2.0407
9m 33s (- 17m 22s) (17750 35%) 2.1027
9m 41s (- 17m 14s) (18000 36%) 2.0396
9m 49s (- 17m 6s) (18250 36%) 1.9195
9m 57s (- 16m 58s) (18500 37%) 1.8826
11m 47s (- 15m 0s) (22000 44%) 1.8047
11m 55s (- 14m 52s) (22250 44%) 1.7742
12m 3s (- 14m 44s) (22500 45%) 1.8339
12m 11s (- 14m 36s) (22750 45%) 1.8410
12m 19s (- 14m 28s) (23000 46%) 1.8805
12m 27s (- 14m 19s) (23250 46%) 1.7419
12m 34s (- 14m 11s) (23500 47%) 1.7621
12m 42s (- 14m 3s) (23750 47%) 1.8105
12m 50s (- 13m 54s) (24000 48%) 1.7943
12m 58s (- 13m 46s) (24250 48%) 1.6676
13m 6s (- 13m 38s) (24500 49%) 1.8287
13m 14s (- 13m 30s) (24750 49%) 1.6563
13m 21s (- 13m 21s) (25000 50%) 1.7273
13m 29s (- 13m 13s) (25250 50%) 1.8329
13m 37s (- 13m 5s) (25500 51%) 1.7469
13m 45s (- 12m 57s) (25750 51%) 1.7384
13m 53s (- 12m 49s) (26000 52%) 1.6652
14m 1s (- 12m 41s) (26250 52%) 1.6037
14m 9s (- 12m 33s) (26500 53%) 1.7191
14m 16s (- 12m 24s) (26750 53%) 1.6973
14m 24s (- 12m 16s) (27000 54%) 1.6083
14m 32s (- 12m 8s) (27250 54%) 1.7156
14m 40s (- 12m 0s) (27500 55%) 1.7280
14m 48s (- 11m 52s) (27750 55%) 1.7159
14m 56s (- 11m 44s) (28000 56%) 1.7114
15m 4s (- 11m 36s) (28250 56%) 1.6274
15m 12s (- 11m 28s) (28500 56%) 1.7392
15m 20s (- 11m 20s) (28750 57%) 1.6450
15m 28s (- 11m 12s) (29000 57%) 1.6486
15m 35s (- 11m 3s) (29250 58%) 1.5500
15m 43s (- 10m 55s) (29500 59%) 1.5396
15m 51s (- 10m 47s) (29750 59%) 1.5874
15m 59s (- 10m 39s) (30000 60%) 1.6781
16m 7s (- 10m 31s) (30250 60%) 1.5464
16m 15s (- 10m 23s) (30500 61%) 1.5097
16m 23s (- 10m 15s) (30750 61%) 1.6336
16m 31s (- 10m 7s) (31000 62%) 1.4506
16m 38s (- 9m 59s) (31250 62%) 1.5574
16m 46s (- 9m 51s) (31500 63%) 1.4673
16m 54s (- 9m 43s) (31750 63%) 1.5363
17m 2s (- 9m 35s) (32000 64%) 1.4984
17m 10s (- 9m 27s) (32250 64%) 1.5828
17m 18s (- 9m 19s) (32500 65%) 1.5599
17m 25s (- 9m 10s) (32750 65%) 1.5457
17m 33s (- 9m 2s) (33000 66%) 1.4696
17m 41s (- 8m 54s) (33250 66%) 1.5849
17m 49s (- 8m 46s) (33500 67%) 1.4862
17m 57s (- 8m 38s) (33750 67%) 1.5384
18m 5s (- 8m 30s) (34000 68%) 1.5472
18m 13s (- 8m 22s) (34250 68%) 1.5177
18m 21s (- 8m 14s) (34500 69%) 1.4774
18m 29s (- 8m 6s) (34750 69%) 1.5311
18m 36s (- 7m 58s) (35000 70%) 1.4315
18m 44s (- 7m 50s) (35250 70%) 1.5333
18m 51s (- 7m 42s) (35500 71%) 1.5042
18m 58s (- 7m 33s) (35750 71%) 1.5169
19m 4s (- 7m 25s) (36000 72%) 1.4865
19m 11s (- 7m 16s) (36250 72%) 1.4325
19m 18s (- 7m 8s) (36500 73%) 1.4366
19m 24s (- 6m 59s) (36750 73%) 1.3897
19m 31s (- 6m 51s) (37000 74%) 1.4056
19m 38s (- 6m 43s) (37250 74%) 1.3767
19m 45s (- 6m 35s) (37500 75%) 1.2663
19m 51s (- 6m 26s) (37750 75%) 1.2585
19m 58s (- 6m 18s) (38000 76%) 1.3711
20m 5s (- 6m 10s) (38250 76%) 1.4283
20m 12s (- 6m 2s) (38500 77%) 1.2946
20m 18s (- 5m 53s) (38750 77%) 1.3490
20m 25s (- 5m 45s) (39000 78%) 1.3680
20m 32s (- 5m 37s) (39250 78%) 1.3051
20m 39s (- 5m 29s) (39500 79%) 1.3372
20m 45s (- 5m 21s) (39750 79%) 1.3481
20m 52s (- 5m 13s) (40000 80%) 1.2466
20m 58s (- 5m 4s) (40250 80%) 1.3027
21m 5s (- 4m 56s) (40500 81%) 1.3294
21m 12s (- 4m 48s) (40750 81%) 1.3335
21m 19s (- 4m 40s) (41000 82%) 1.3182
21m 26s (- 4m 32s) (41250 82%) 1.2889
21m 32s (- 4m 24s) (41500 83%) 1.2759
21m 39s (- 4m 16s) (41750 83%) 1.1475
21m 45s (- 4m 8s) (42000 84%) 1.3096
21m 51s (- 4m 0s) (42250 84%) 1.3623
21m 56s (- 3m 52s) (42500 85%) 1.1836
22m 2s (- 3m 44s) (42750 85%) 1.2626
22m 8s (- 3m 36s) (43000 86%) 1.3089
22m 13s (- 3m 28s) (43250 86%) 1.3444
22m 17s (- 3m 19s) (43500 87%) 1.1942
22m 22s (- 3m 11s) (43750 87%) 1.1610
22m 27s (- 3m 3s) (44000 88%) 1.2403
22m 31s (- 2m 55s) (44250 88%) 1.2399
22m 36s (- 2m 47s) (44500 89%) 1.1469
22m 41s (- 2m 39s) (44750 89%) 1.2939
22m 45s (- 2m 31s) (45000 90%) 1.1891
22m 50s (- 2m 23s) (45250 90%) 1.1746
22m 55s (- 2m 16s) (45500 91%) 1.2312
23m 0s (- 2m 8s) (45750 91%) 1.1844
23m 4s (- 2m 0s) (46000 92%) 1.2206
23m 9s (- 1m 52s) (46250 92%) 1.1198
23m 14s (- 1m 44s) (46500 93%) 1.1725
23m 19s (- 1m 37s) (46750 93%) 1.1767
23m 23s (- 1m 29s) (47000 94%) 1.0955
23m 28s (- 1m 21s) (47250 94%) 1.1346
23m 33s (- 1m 14s) (47500 95%) 1.2594
23m 38s (- 1m 6s) (47750 95%) 1.1463
23m 43s (- 0m 59s) (48000 96%) 1.0840
23m 47s (- 0m 51s) (48250 96%) 1.2354
23m 52s (- 0m 44s) (48500 97%) 1.1347
23m 56s (- 0m 36s) (48750 97%) 1.1060
24m 1s (- 0m 29s) (49000 98%) 1.1978
24m 6s (- 0m 22s) (49250 98%) 1.1906
24m 11s (- 0m 14s) (49500 99%) 1.0553
24m 15s (- 0m 7s) (49750 99%) 1.1334
24m 20s (- 0m 0s) (50000 100%) 1.0692
<Figure size 432x288 with 0 Axes>

# Hw 1.3
# TODO: change activation of DecoderLSTM firstly
class DecoderLSTM_v2(nn.Module):
"""Decoder use LSTM as backbone"""
def __init__(self, hidden_size: int, output_size: int):
"""
Args:
hidden_size: The number of features in the hidden state
output_size : The number of expected features in the output
"""
super(DecoderLSTM_v2, self).__init__()
self.hidden_size = hidden_size
# Retrieve word embeddings with dimentionality hidden_size
# using indices with dimentionality input_size, embeddding is learnable
# After embedding, input vector with input_size would be converted to hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
# LSTM
self.lstm = nn.LSTM(hidden_size, hidden_size)
# out
self.out = nn.Linear(hidden_size, output_size)
# log after softmax
self.log_softmax = nn.LogSoftmax(dim=1)
# activation function, TODO!!
self.activation_function = torch.tanh
def forward(self, inputs, state):
"""Forward
Args:
inputs: [1, hidden_size]
state : ([1, 1, hidden_size], [1, 1, hidden_size])
Returns:
output:
state: (hidden, cell)
"""
(hidden, cell) = state
# Retrieve word embeddings, [1, 1, hidden_size]
output = self.embedding(inputs).view(1, 1, -1)
# activation function, [1, 1, hidden_size]
output = self.activation_function(output)
# output: [1, 1, hidden_size]
output, (hidden, cell) = self.lstm(output, (hidden, cell))
# output: [output_size]
output = self.log_softmax(self.out(output[0]))
return output, (hidden, cell)
def init_hidden(self):
"""Init hidden
Returns:
hidden:
cell:
"""
cell = torch.zeros(1, 1, self.hidden_size, device=device)
hidden = torch.zeros(1, 1, self.hidden_size, device=device)
return hidden, cell
setup_seed(45)
hidden_size = 256
# Reverse the order of source input sentence
reverse_source_sentence = True
# Feed the target as the next input
use_teacher_forcing = True
encoder = EncoderLSTM(input_lang.n_words, hidden_size).to(device)
decoder = DecoderLSTM_v2(hidden_size, output_lang.n_words).to(device)
print(">> Model is on: {}".format(next(encoder.parameters()).is_cuda))
print(">> Model is on: {}".format(next(decoder.parameters()).is_cuda))
iters = 50000
train(encoder, decoder, iters, reverse_source_sentence=reverse_source_sentence,
use_teacher_forcing=use_teacher_forcing,print_every=250, plot_every=250)
>> Model is on: True
>> Model is on: True
0m 7s (- 24m 31s) (250 0%) 5.4118
0m 13s (- 22m 31s) (500 1%) 3.4440
0m 19s (- 21m 50s) (750 1%) 3.1115
0m 26s (- 21m 25s) (1000 2%) 2.9068
0m 32s (- 21m 8s) (1250 2%) 2.8706
0m 38s (- 20m 57s) (1500 3%) 2.7711
0m 45s (- 20m 45s) (1750 3%) 2.7297
0m 51s (- 20m 34s) (2000 4%) 2.7282
0m 57s (- 20m 27s) (2250 4%) 2.6766
1m 4s (- 20m 19s) (2500 5%) 2.6640
1m 10s (- 20m 17s) (2750 5%) 2.6400
1m 17s (- 20m 6s) (3000 6%) 2.5584
1m 23s (- 19m 58s) (3250 6%) 2.5408
1m 29s (- 19m 51s) (3500 7%) 2.5797
1m 35s (- 19m 43s) (3750 7%) 2.5578
1m 42s (- 19m 37s) (4000 8%) 2.4568
1m 48s (- 19m 30s) (4250 8%) 2.4575
1m 55s (- 19m 23s) (4500 9%) 2.3789
2m 1s (- 19m 15s) (4750 9%) 2.3421
2m 7s (- 19m 7s) (5000 10%) 2.3405
2m 13s (- 18m 58s) (5250 10%) 2.3912
2m 19s (- 18m 52s) (5500 11%) 2.3813
2m 26s (- 18m 45s) (5750 11%) 2.3159
2m 32s (- 18m 41s) (6000 12%) 2.3369
2m 39s (- 18m 35s) (6250 12%) 2.2909
2m 45s (- 18m 28s) (6500 13%) 2.2288
2m 51s (- 18m 21s) (6750 13%) 2.1220
2m 58s (- 18m 15s) (7000 14%) 2.2243
3m 4s (- 18m 8s) (7250 14%) 2.2551
3m 10s (- 18m 1s) (7500 15%) 2.1419
3m 17s (- 17m 55s) (7750 15%) 2.1616
3m 23s (- 17m 49s) (8000 16%) 2.1254
3m 29s (- 17m 42s) (8250 16%) 2.0929
3m 36s (- 17m 37s) (8500 17%) 2.1534
3m 43s (- 17m 31s) (8750 17%) 2.0851
3m 49s (- 17m 26s) (9000 18%) 2.0738
3m 55s (- 17m 19s) (9250 18%) 1.9404
4m 2s (- 17m 12s) (9500 19%) 2.0076
4m 8s (- 17m 5s) (9750 19%) 1.9080
4m 14s (- 16m 59s) (10000 20%) 2.0130
4m 20s (- 16m 51s) (10250 20%) 1.9649
4m 26s (- 16m 43s) (10500 21%) 1.8951
4m 33s (- 16m 37s) (10750 21%) 1.9457
4m 39s (- 16m 31s) (11000 22%) 1.9487
4m 45s (- 16m 25s) (11250 22%) 1.8837
4m 52s (- 16m 19s) (11500 23%) 1.9643
4m 58s (- 16m 13s) (11750 23%) 1.8865
5m 5s (- 16m 7s) (12000 24%) 1.7592
5m 11s (- 16m 0s) (12250 24%) 1.8790
5m 17s (- 15m 53s) (12500 25%) 1.8230
5m 24s (- 15m 47s) (12750 25%) 1.9465
5m 30s (- 15m 41s) (13000 26%) 1.8486
5m 37s (- 15m 34s) (13250 26%) 1.8044
5m 43s (- 15m 28s) (13500 27%) 1.7861
5m 49s (- 15m 22s) (13750 27%) 1.8498
5m 56s (- 15m 16s) (14000 28%) 1.7992
6m 2s (- 15m 9s) (14250 28%) 1.8050
6m 8s (- 15m 3s) (14500 28%) 1.7724
6m 15s (- 14m 56s) (14750 29%) 1.7104
6m 21s (- 14m 50s) (15000 30%) 1.6796
6m 28s (- 14m 44s) (15250 30%) 1.7817
6m 34s (- 14m 38s) (15500 31%) 1.7459
6m 40s (- 14m 31s) (15750 31%) 1.6660
6m 47s (- 14m 25s) (16000 32%) 1.6038
6m 53s (- 14m 19s) (16250 32%) 1.7209
7m 0s (- 14m 12s) (16500 33%) 1.7453
7m 5s (- 14m 5s) (16750 33%) 1.6432
7m 11s (- 13m 57s) (17000 34%) 1.6812
7m 16s (- 13m 49s) (17250 34%) 1.6068
7m 23s (- 13m 43s) (17500 35%) 1.6077
7m 29s (- 13m 37s) (17750 35%) 1.6540
7m 35s (- 13m 29s) (18000 36%) 1.6522
7m 41s (- 13m 22s) (18250 36%) 1.5541
7m 46s (- 13m 14s) (18500 37%) 1.4592
7m 52s (- 13m 7s) (18750 37%) 1.5580
7m 57s (- 12m 59s) (19000 38%) 1.5883
8m 3s (- 12m 51s) (19250 38%) 1.4840
8m 8s (- 12m 44s) (19500 39%) 1.5447
8m 13s (- 12m 36s) (19750 39%) 1.5163
8m 19s (- 12m 28s) (20000 40%) 1.4560
8m 24s (- 12m 21s) (20250 40%) 1.5119
8m 30s (- 12m 14s) (20500 41%) 1.5253
8m 35s (- 12m 6s) (20750 41%) 1.5125
8m 41s (- 11m 59s) (21000 42%) 1.5314
8m 46s (- 11m 52s) (21250 42%) 1.4621
8m 52s (- 11m 45s) (21500 43%) 1.5241
8m 57s (- 11m 38s) (21750 43%) 1.5766
9m 3s (- 11m 32s) (22000 44%) 1.4428
9m 10s (- 11m 26s) (22250 44%) 1.3960
9m 15s (- 11m 19s) (22500 45%) 1.4166
9m 20s (- 11m 11s) (22750 45%) 1.4751
9m 26s (- 11m 5s) (23000 46%) 1.4560
9m 32s (- 10m 58s) (23250 46%) 1.3324
9m 37s (- 10m 51s) (23500 47%) 1.3579
9m 43s (- 10m 44s) (23750 47%) 1.4121
9m 48s (- 10m 37s) (24000 48%) 1.4008
9m 54s (- 10m 31s) (24250 48%) 1.3320
10m 0s (- 10m 24s) (24500 49%) 1.4318
10m 5s (- 10m 17s) (24750 49%) 1.2667
10m 11s (- 10m 11s) (25000 50%) 1.3110
10m 17s (- 10m 5s) (25250 50%) 1.4134
10m 22s (- 9m 58s) (25500 51%) 1.3328
10m 28s (- 9m 51s) (25750 51%) 1.3002
10m 33s (- 9m 45s) (26000 52%) 1.2974
10m 39s (- 9m 38s) (26250 52%) 1.2296
10m 44s (- 9m 31s) (26500 53%) 1.3079
10m 50s (- 9m 25s) (26750 53%) 1.2736
10m 56s (- 9m 19s) (27000 54%) 1.1862
11m 1s (- 9m 12s) (27250 54%) 1.2917
11m 7s (- 9m 6s) (27500 55%) 1.3090
11m 13s (- 8m 59s) (27750 55%) 1.2842
11m 18s (- 8m 53s) (28000 56%) 1.3294
11m 24s (- 8m 46s) (28250 56%) 1.2652
11m 29s (- 8m 40s) (28500 56%) 1.3036
11m 35s (- 8m 33s) (28750 57%) 1.2516
11m 40s (- 8m 27s) (29000 57%) 1.2109
11m 46s (- 8m 21s) (29250 58%) 1.1726
11m 52s (- 8m 14s) (29500 59%) 1.1645
11m 57s (- 8m 8s) (29750 59%) 1.1421
12m 3s (- 8m 2s) (30000 60%) 1.2620
12m 8s (- 7m 55s) (30250 60%) 1.1545
12m 14s (- 7m 49s) (30500 61%) 1.1347
12m 19s (- 7m 43s) (30750 61%) 1.2216
12m 25s (- 7m 36s) (31000 62%) 1.1070
12m 31s (- 7m 30s) (31250 62%) 1.1662
12m 36s (- 7m 24s) (31500 63%) 1.1051
12m 42s (- 7m 18s) (31750 63%) 1.1288
12m 47s (- 7m 11s) (32000 64%) 1.0735
12m 53s (- 7m 5s) (32250 64%) 1.1689
12m 58s (- 6m 59s) (32500 65%) 1.1648
13m 3s (- 6m 52s) (32750 65%) 1.1337
13m 8s (- 6m 45s) (33000 66%) 1.0650
13m 13s (- 6m 39s) (33250 66%) 1.2024
13m 17s (- 6m 33s) (33500 67%) 1.0940
13m 22s (- 6m 26s) (33750 67%) 1.1060
13m 27s (- 6m 20s) (34000 68%) 1.1126
13m 32s (- 6m 13s) (34250 68%) 1.1412
13m 38s (- 6m 7s) (34500 69%) 1.0815
13m 44s (- 6m 1s) (34750 69%) 1.0864
13m 50s (- 5m 55s) (35000 70%) 1.0517
13m 56s (- 5m 50s) (35250 70%) 1.0901
14m 2s (- 5m 43s) (35500 71%) 1.0965
14m 7s (- 5m 37s) (35750 71%) 1.1462
14m 13s (- 5m 31s) (36000 72%) 1.0654
14m 18s (- 5m 25s) (36250 72%) 0.9683
14m 25s (- 5m 20s) (36500 73%) 1.0852
14m 31s (- 5m 14s) (36750 73%) 1.0260
14m 37s (- 5m 8s) (37000 74%) 1.0323
14m 44s (- 5m 2s) (37250 74%) 1.0400
14m 51s (- 4m 57s) (37500 75%) 0.9172
14m 58s (- 4m 51s) (37750 75%) 0.9479
15m 5s (- 4m 45s) (38000 76%) 0.9919
15m 12s (- 4m 40s) (38250 76%) 1.0249
15m 19s (- 4m 34s) (38500 77%) 0.9339
15m 26s (- 4m 28s) (38750 77%) 0.9684
15m 33s (- 4m 23s) (39000 78%) 0.9866
15m 40s (- 4m 17s) (39250 78%) 0.9021
15m 47s (- 4m 11s) (39500 79%) 0.9421
15m 54s (- 4m 6s) (39750 79%) 0.9982
16m 1s (- 4m 0s) (40000 80%) 0.8918
16m 8s (- 3m 54s) (40250 80%) 0.9356
16m 15s (- 3m 48s) (40500 81%) 0.9880
16m 22s (- 3m 42s) (40750 81%) 1.0126
16m 29s (- 3m 37s) (41000 82%) 0.8997
16m 36s (- 3m 31s) (41250 82%) 0.9651
16m 43s (- 3m 25s) (41500 83%) 0.9271
16m 49s (- 3m 19s) (41750 83%) 0.8294
16m 56s (- 3m 13s) (42000 84%) 0.8939
17m 4s (- 3m 7s) (42250 84%) 0.9690
17m 11s (- 3m 1s) (42500 85%) 0.8294
17m 17s (- 2m 55s) (42750 85%) 0.9057
17m 24s (- 2m 49s) (43000 86%) 0.9040
17m 31s (- 2m 44s) (43250 86%) 0.9020
17m 38s (- 2m 38s) (43500 87%) 0.8598
17m 45s (- 2m 32s) (43750 87%) 0.7808
17m 51s (- 2m 26s) (44000 88%) 0.8651
17m 58s (- 2m 20s) (44250 88%) 0.8298
18m 5s (- 2m 14s) (44500 89%) 0.8292
18m 12s (- 2m 8s) (44750 89%) 0.9227
18m 19s (- 2m 2s) (45000 90%) 0.8551
18m 26s (- 1m 56s) (45250 90%) 0.7870
18m 32s (- 1m 50s) (45500 91%) 0.8815
18m 40s (- 1m 44s) (45750 91%) 0.8191
18m 47s (- 1m 38s) (46000 92%) 0.8107
18m 54s (- 1m 31s) (46250 92%) 0.7644
19m 1s (- 1m 25s) (46500 93%) 0.7996
19m 8s (- 1m 19s) (46750 93%) 0.7954
19m 14s (- 1m 13s) (47000 94%) 0.7589
19m 23s (- 1m 7s) (47250 94%) 0.7825
19m 31s (- 1m 1s) (47500 95%) 0.8812
19m 39s (- 0m 55s) (47750 95%) 0.8011
19m 47s (- 0m 49s) (48000 96%) 0.7464
19m 55s (- 0m 43s) (48250 96%) 0.8238
20m 4s (- 0m 37s) (48500 97%) 0.7181
20m 12s (- 0m 31s) (48750 97%) 0.7389
20m 20s (- 0m 24s) (49000 98%) 0.8540
20m 28s (- 0m 18s) (49250 98%) 0.8352
20m 36s (- 0m 12s) (49500 99%) 0.7494
20m 45s (- 0m 6s) (49750 99%) 0.8223
20m 53s (- 0m 0s) (50000 100%) 0.7700
<Figure size 432x288 with 0 Axes>

1.2 Decoder with Attention
Why we need attention mechanism ?
In short version, because seq2seq could achieve better performance and consumes less time with attention mechanism.
In long version, attention allows the decoder network to “focus” on a different part of the encoder’s outputs for every step of the decoder’s own outputs.
For simplicity, we change DecoderLSTM to AttentionDecoderLSTM and some hepler function and then
we can train model.
Very Detail of AttentionDecoderLSTM
Since there are many ways to do attention, we select a simple way to do that.
First we calculate a set of attention weights.
These will be multiplied by the encoder output vectors to create a weighted combination.
The result (called attention_applied in the code) should contain information about that
specific part of the input sequence, and thus help the decoder choose the right output words.

class AttentionDecoderLSTM(nn.Module):
def __init__(self, hidden_size: int, output_size: int, dropout_p=0.1, max_length=MAX_LENGTH):
"""DecoderLSTM with attention mechanism
"""
super(AttentionDecoderLSTM, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
# Retrieve word embeddings with dimentionality hidden_size
# using indices with dimentionality input_size, embeddding is learnable
# After embedding, input vector with input_size would be converted to hidden_size
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
# W1
self.attention = nn.Linear(self.hidden_size * 2, self.max_length)
# W2
self.attention_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.lstm = nn.LSTM(self.hidden_size, self.hidden_size)
# prediction layer
self.out = nn.Linear(self.hidden_size, self.output_size)
# activation
self.activation_fn = F.relu
def forward(self, inputs, state, encoder_outputs):
"""Forward
Args:
inputs: [1, hidden_size]
state : ([1, 1, hidden_size], [1, 1, hidden_size])
encoder_outputs: [max_length, hidden_size]
Returns:
output:
state: (hidden, cell)
"""
# embedded: [1, 1, hidden_size]
embedded = self.embedding(inputs).view(1, 1, -1)
embedded = self.dropout(embedded)
(hidden, cell) = state
# attention_weights: [1, max_length]
attention_weights = F.softmax(
self.attention(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
# attention_applied: [1, hidden_size]
# torch.bmm == @, matrix muplication
attention_applied = torch.bmm(attention_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
# output: [1, hidden_size * 2]
output = torch.cat((embedded[0], attention_applied[0]), 1)
# output: [1, 1, hidden_size]
output = self.attention_combine(output).unsqueeze(0)
output = self.activation_fn(output)
# output, [1, 1, output_size]
output, (hidden, cell) = self.lstm(output, (hidden, cell))
# output, [1, output_size]
output = F.log_softmax(self.out(output[0]), dim=1)
return output, (hidden, cell), attention_weights
def init_hidden(self):
"""Init hidden
Returns:
hidden:
cell:
"""
cell = torch.zeros(1, 1, self.hidden_size, device=device)
hidden = torch.zeros(1, 1, self.hidden_size, device=device)
return hidden, cell
def train_by_sentence_attn(input_tensor, target_tensor, encoder, decoder,
encoder_optimizer, decoder_optimizer, loss_fn,
use_teacher_forcing=True, reverse_source_sentence=True,
max_length=MAX_LENGTH):
"""Train by single sentence using EncoderLSTM and DecoderLSTM
including training and update model, combining attention mechanism.
Args:
input_tensor: [input_sequence_len, 1, hidden_size]
target_tensor: [target_sequence_len, 1, hidden_size]
encoder: EncoderLSTM
decoder: DecoderLSTM
encoder_optimizer: optimizer for encoder
decoder_optimizer: optimizer for decoder
loss_fn: loss function
use_teacher_forcing: True is to Feed the target as the next input,
False is to use its own predictions as the next input
max_length: max length for input and output
Returns:
loss: scalar
"""
if reverse_source_sentence:
input_tensor = torch.flip(input_tensor, [0])
hidden, cell = encoder.init_hidden()
# Clears the gradients of all optimized torch.Tensors'
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
# Get sequence length of the input and target sentences.
input_length = input_tensor.size(0)
target_length = target_tensor.size(0)
# encoder outputs: [max_length, hidden_size]
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
loss = 0
# Get encoder outputs
for ei in range(input_length):
encoder_output, (hidden, cell) = encoder(
input_tensor[ei], (hidden, cell))
encoder_outputs[ei] = encoder_output[0, 0]
# First input for the decoder
decoder_input = torch.tensor([[SOS_token]], device=device)
# Last state of encoder as the init state of decoder
decoder_hidden = (hidden, cell)
for di in range(target_length):
# !! Most important change, apply attention mechnism
decoder_output, (hidden, cell), _ = decoder(
decoder_input, (hidden, cell), encoder_outputs)
if use_teacher_forcing:
# Feed the target as the next input
loss += loss_fn(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # Teacher forcing
else:
# Use its own predictions as the next input
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach()
loss += loss_fn(decoder_output, target_tensor[di])
# End if decoder output End of Signal(EOS)
if decoder_input.item() == EOS_token:
break
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / target_length
def train_attn(encoder, decoder, n_iters, reverse_source_sentence=True,
use_teacher_forcing=True,
print_every=1000, plot_every=100,
learning_rate=0.01):
"""Train of Seq2seq with attention
Args:
encoder: EncoderLSTM
decoder: DecoderLSTM
n_iters: train with n_iters sentences without replacement
reverse_source_sentence: True is to reverse the source sentence
but keep order of target unchanged,
False is to keep order of the source sentence
target unchanged
use_teacher_forcing: True is to Feed the target as the next input,
False is to use its own predictions as the next input
print_every: print log every print_every
plot_every: plot every plot_every
learning_rate:
"""
start = time.time()
plot_losses = []
print_loss_total = 0
plot_loss_total = 0
# Use SGD to optimize encoder and decoder parameters
encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate)
# Obtain training input
training_pairs = [tensor_from_pair(random.choice(pairs), input_lang, output_lang)
for _ in range(n_iters)]
# Negative log likelihood loss
loss_fn = nn.NLLLoss()
for i in range(1, n_iters+1):
# Get a pair of sentences and move them to device,
# training_pair: ([Seq_size, 1, input_size], [Seq_size, 1, input_size])
training_pair = training_pairs[i-1]
input_tensor = training_pair[0].to(device)
target_tensor = training_pair[1].to(device)
# Train by a pair of source sentence and target sentence
loss = train_by_sentence_attn(input_tensor, target_tensor,
encoder, decoder,
encoder_optimizer, decoder_optimizer,
loss_fn, use_teacher_forcing=use_teacher_forcing,
reverse_source_sentence=reverse_source_sentence)
print_loss_total += loss
plot_loss_total += loss
if i % print_every == 0:
# Print Loss
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print("%s (%d %d%%) %.4f" % (time_since(start, i / n_iters),
i, i / n_iters * 100, print_loss_avg))
if i % plot_every == 0:
# Plot
plot_loss_avg = plot_loss_total / plot_every
plot_losses.append(plot_loss_avg)
plot_loss_total = 0
# show plot
show_plot(plot_losses)
def evaluate_by_sentence_attn(encoder, decoder, sentence,
reverse_source_sentence=True, max_length=MAX_LENGTH):
"""Evalutae on a source sentence with model trained with attention mechanism
Args:
encoder
decoder
sentence
max_length
Return:
decoded_words: predicted sentence
"""
with torch.no_grad():
# Get tensor of sentence
input_tensor = tensor_from_sentence(input_lang, sentence).to(device)
input_length = input_tensor.size(0)
if reverse_source_sentence:
input_tensor = torch.flip(input_tensor, [0])
# init state for encoder
(hidden, cell) = encoder.init_hidden()
# encoder outputs: [max_length, hidden_size]
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
for ei in range(input_length):
encoder_output, (hidden, cell) = encoder(input_tensor[ei],
(hidden, cell))
encoder_outputs[ei] += encoder_output[0, 0]
# Last state of encoder as the init state of decoder
decoder_input = torch.tensor([[SOS_token]], device=device)
decoder_hidden = (hidden, cell)
decoded_words = []
# CHANGE!! Add decoder_attentions to collect attention map
decoder_attentions = torch.zeros(max_length, max_length)
# When evaluate, use its own predictions as the next input
for di in range(max_length):
# CHANGE!! Attention
decoder_output, (hidden, cell), decoder_attention = \
decoder(decoder_input, (hidden, cell), encoder_outputs)
topv, topi = decoder_output.data.topk(1)
# CHANGE!!
decoder_attentions[di] = decoder_attention.data
if topi.item() == EOS_token:
decoded_words.append("<EOS>")
break
else:
decoded_words.append(output_lang.index2word[topi.item()])
decoder_input = topi.squeeze().detach()
return decoded_words, decoder_attentions[:di + 1]
def show_attention(input_sentence, output_words, attentions):
"""Show attention between input sentence and output words
"""
# Set up figure with colorbar
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(attentions.numpy(), cmap='bone')
fig.colorbar(cax)
# Set up axes
ax.set_xticklabels([''] + input_sentence.split(' ') +
['<EOS>'], rotation=90)
ax.set_yticklabels([''] + output_words)
# Show label at every tick
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()
def evaluate_and_show_attention(input_sentence, encoder, decoder):
"""Evaluate and show attention for a input sentence
"""
output_words, attentions = evaluate_by_sentence_attn(
encoder, decoder, input_sentence)
print('input =', input_sentence)
print('output =', ' '.join(output_words))
show_attention(input_sentence, output_words, attentions)
setup_seed(45)
hidden_size = 256
# Reverse the order of source input sentence
reverse_source_sentence = True
# Feed the target as the next input
use_teacher_forcing = True
encoder = EncoderLSTM(input_lang.n_words, hidden_size).to(device)
decoder = AttentionDecoderLSTM(hidden_size, output_lang.n_words).to(device)
print(">> Model is on: {}".format(next(encoder.parameters()).is_cuda))
print(">> Model is on: {}".format(next(decoder.parameters()).is_cuda))
>> Model is on: True
>> Model is on: True
iters = 50000
train_attn(encoder, decoder, iters, reverse_source_sentence=reverse_source_sentence,
use_teacher_forcing=use_teacher_forcing,print_every=250, plot_every=250)
0m 12s (- 39m 56s) (250 0%) 4.9045
0m 23s (- 38m 1s) (500 1%) 3.3049
0m 33s (- 36m 48s) (750 1%) 3.0303
0m 43s (- 35m 52s) (1000 2%) 2.8569
0m 54s (- 35m 44s) (1250 2%) 2.8321
1m 6s (- 35m 37s) (1500 3%) 2.7320
1m 16s (- 35m 11s) (1750 3%) 2.6652
1m 26s (- 34m 37s) (2000 4%) 2.6601
1m 37s (- 34m 26s) (2250 4%) 2.6078
1m 48s (- 34m 14s) (2500 5%) 2.5934
1m 58s (- 33m 57s) (2750 5%) 2.5855
2m 9s (- 33m 42s) (3000 6%) 2.4951
2m 19s (- 33m 28s) (3250 6%) 2.4717
2m 30s (- 33m 23s) (3500 7%) 2.4963
2m 41s (- 33m 14s) (3750 7%) 2.4969
2m 52s (- 33m 5s) (4000 8%) 2.3994
3m 3s (- 32m 51s) (4250 8%) 2.3991
3m 14s (- 32m 42s) (4500 9%) 2.3072
3m 24s (- 32m 28s) (4750 9%) 2.2703
3m 35s (- 32m 15s) (5000 10%) 2.2681
3m 45s (- 32m 3s) (5250 10%) 2.3253
3m 56s (- 31m 54s) (5500 11%) 2.3062
4m 7s (- 31m 42s) (5750 11%) 2.2431
4m 18s (- 31m 34s) (6000 12%) 2.2481
4m 29s (- 31m 26s) (6250 12%) 2.2147
4m 40s (- 31m 14s) (6500 13%) 2.1789
4m 50s (- 31m 2s) (6750 13%) 2.0689
5m 1s (- 30m 52s) (7000 14%) 2.1624
5m 12s (- 30m 44s) (7250 14%) 2.1783
5m 23s (- 30m 33s) (7500 15%) 2.0618
5m 34s (- 30m 25s) (7750 15%) 2.0752
5m 44s (- 30m 6s) (8000 16%) 2.0351
5m 53s (- 29m 47s) (8250 16%) 2.0126
6m 2s (- 29m 30s) (8500 17%) 2.0556
6m 11s (- 29m 13s) (8750 17%) 2.0194
6m 21s (- 28m 56s) (9000 18%) 2.0155
6m 29s (- 28m 37s) (9250 18%) 1.8749
6m 38s (- 28m 19s) (9500 19%) 1.9430
6m 47s (- 28m 2s) (9750 19%) 1.8124
6m 56s (- 27m 46s) (10000 20%) 1.9113
7m 5s (- 27m 30s) (10250 20%) 1.8959
7m 14s (- 27m 15s) (10500 21%) 1.8226
7m 24s (- 27m 1s) (10750 21%) 1.8846
7m 33s (- 26m 46s) (11000 22%) 1.8598
7m 42s (- 26m 31s) (11250 22%) 1.8070
7m 51s (- 26m 17s) (11500 23%) 1.8770
8m 0s (- 26m 4s) (11750 23%) 1.7991
8m 9s (- 25m 48s) (12000 24%) 1.6979
8m 18s (- 25m 35s) (12250 24%) 1.7849
8m 27s (- 25m 22s) (12500 25%) 1.7383
8m 36s (- 25m 9s) (12750 25%) 1.8461
8m 45s (- 24m 56s) (13000 26%) 1.7735
8m 54s (- 24m 42s) (13250 26%) 1.7250
9m 3s (- 24m 30s) (13500 27%) 1.7031
9m 13s (- 24m 17s) (13750 27%) 1.7557
9m 22s (- 24m 6s) (14000 28%) 1.7034
9m 31s (- 23m 54s) (14250 28%) 1.7474
9m 41s (- 23m 42s) (14500 28%) 1.7002
9m 50s (- 23m 30s) (14750 29%) 1.6098
9m 59s (- 23m 18s) (15000 30%) 1.6132
10m 8s (- 23m 7s) (15250 30%) 1.7066
10m 18s (- 22m 56s) (15500 31%) 1.6781
10m 27s (- 22m 45s) (15750 31%) 1.5791
10m 36s (- 22m 32s) (16000 32%) 1.5366
10m 45s (- 22m 21s) (16250 32%) 1.6449
10m 55s (- 22m 10s) (16500 33%) 1.6655
11m 5s (- 22m 0s) (16750 33%) 1.5604
11m 14s (- 21m 48s) (17000 34%) 1.5838
11m 23s (- 21m 37s) (17250 34%) 1.5468
11m 33s (- 21m 27s) (17500 35%) 1.5449
11m 41s (- 21m 15s) (17750 35%) 1.5705
11m 49s (- 21m 2s) (18000 36%) 1.5782
11m 57s (- 20m 48s) (18250 36%) 1.4957
12m 5s (- 20m 35s) (18500 37%) 1.3964
12m 13s (- 20m 22s) (18750 37%) 1.4830
12m 21s (- 20m 10s) (19000 38%) 1.5285
12m 30s (- 19m 58s) (19250 38%) 1.4140
12m 37s (- 19m 45s) (19500 39%) 1.4499
12m 45s (- 19m 32s) (19750 39%) 1.4234
12m 54s (- 19m 21s) (20000 40%) 1.4060
13m 3s (- 19m 10s) (20250 40%) 1.4435
13m 12s (- 19m 0s) (20500 41%) 1.4514
13m 21s (- 18m 50s) (20750 41%) 1.4453
13m 31s (- 18m 40s) (21000 42%) 1.4741
13m 40s (- 18m 30s) (21250 42%) 1.3784
13m 50s (- 18m 20s) (21500 43%) 1.4439
13m 59s (- 18m 9s) (21750 43%) 1.4836
14m 8s (- 18m 0s) (22000 44%) 1.3703
14m 18s (- 17m 50s) (22250 44%) 1.3226
14m 27s (- 17m 40s) (22500 45%) 1.3610
14m 37s (- 17m 30s) (22750 45%) 1.4003
14m 48s (- 17m 23s) (23000 46%) 1.3914
14m 59s (- 17m 14s) (23250 46%) 1.2699
15m 10s (- 17m 6s) (23500 47%) 1.2957
15m 21s (- 16m 58s) (23750 47%) 1.3403
15m 32s (- 16m 50s) (24000 48%) 1.3439
15m 42s (- 16m 41s) (24250 48%) 1.2482
15m 54s (- 16m 32s) (24500 49%) 1.3789
16m 4s (- 16m 23s) (24750 49%) 1.1900
16m 15s (- 16m 15s) (25000 50%) 1.2474
16m 26s (- 16m 6s) (25250 50%) 1.3320
16m 37s (- 15m 58s) (25500 51%) 1.2478
16m 48s (- 15m 49s) (25750 51%) 1.2392
16m 59s (- 15m 40s) (26000 52%) 1.2369
17m 10s (- 15m 31s) (26250 52%) 1.1629
17m 21s (- 15m 23s) (26500 53%) 1.2625
17m 31s (- 15m 14s) (26750 53%) 1.2236
17m 42s (- 15m 5s) (27000 54%) 1.1323
17m 54s (- 14m 56s) (27250 54%) 1.2009
18m 4s (- 14m 47s) (27500 55%) 1.2412
18m 15s (- 14m 38s) (27750 55%) 1.2053
18m 27s (- 14m 30s) (28000 56%) 1.2504
18m 38s (- 14m 21s) (28250 56%) 1.1889
18m 49s (- 14m 12s) (28500 56%) 1.2637
19m 0s (- 14m 3s) (28750 57%) 1.2014
19m 11s (- 13m 53s) (29000 57%) 1.1773
19m 22s (- 13m 44s) (29250 58%) 1.1245
19m 33s (- 13m 35s) (29500 59%) 1.1128
19m 44s (- 13m 26s) (29750 59%) 1.1001
19m 55s (- 13m 16s) (30000 60%) 1.2020
20m 6s (- 13m 7s) (30250 60%) 1.0931
20m 16s (- 12m 57s) (30500 61%) 1.0847
20m 27s (- 12m 48s) (30750 61%) 1.1683
20m 38s (- 12m 38s) (31000 62%) 1.0578
20m 49s (- 12m 29s) (31250 62%) 1.1204
21m 0s (- 12m 20s) (31500 63%) 1.0375
21m 11s (- 12m 10s) (31750 63%) 1.0673
21m 22s (- 12m 1s) (32000 64%) 1.0291
21m 33s (- 11m 51s) (32250 64%) 1.1162
21m 44s (- 11m 42s) (32500 65%) 1.1235
21m 55s (- 11m 32s) (32750 65%) 1.0975
22m 5s (- 11m 22s) (33000 66%) 1.0241
22m 16s (- 11m 13s) (33250 66%) 1.1561
22m 27s (- 11m 3s) (33500 67%) 1.0525
22m 38s (- 10m 54s) (33750 67%) 1.0605
22m 49s (- 10m 44s) (34000 68%) 1.0551
23m 0s (- 10m 34s) (34250 68%) 1.0728
23m 10s (- 10m 24s) (34500 69%) 1.0422
23m 20s (- 10m 14s) (34750 69%) 1.0189
23m 29s (- 10m 4s) (35000 70%) 0.9925
23m 38s (- 9m 53s) (35250 70%) 1.0572
23m 45s (- 9m 42s) (35500 71%) 1.0211
23m 53s (- 9m 31s) (35750 71%) 1.0857
24m 0s (- 9m 20s) (36000 72%) 1.0427
24m 7s (- 9m 9s) (36250 72%) 0.9366
24m 14s (- 8m 58s) (36500 73%) 1.0282
24m 22s (- 8m 47s) (36750 73%) 0.9766
24m 29s (- 8m 36s) (37000 74%) 0.9918
24m 37s (- 8m 25s) (37250 74%) 0.9713
24m 45s (- 8m 15s) (37500 75%) 0.8682
24m 53s (- 8m 4s) (37750 75%) 0.8866
25m 1s (- 7m 54s) (38000 76%) 0.9383
25m 9s (- 7m 43s) (38250 76%) 0.9673
25m 16s (- 7m 33s) (38500 77%) 0.8919
25m 24s (- 7m 22s) (38750 77%) 0.9282
25m 31s (- 7m 12s) (39000 78%) 0.9390
25m 38s (- 7m 1s) (39250 78%) 0.8759
25m 45s (- 6m 50s) (39500 79%) 0.9049
25m 53s (- 6m 40s) (39750 79%) 0.9363
25m 59s (- 6m 29s) (40000 80%) 0.8546
26m 6s (- 6m 19s) (40250 80%) 0.8826
26m 13s (- 6m 9s) (40500 81%) 0.9364
26m 20s (- 5m 58s) (40750 81%) 0.9326
26m 27s (- 5m 48s) (41000 82%) 0.8726
26m 34s (- 5m 38s) (41250 82%) 0.9256
26m 41s (- 5m 28s) (41500 83%) 0.8858
26m 48s (- 5m 17s) (41750 83%) 0.7803
26m 55s (- 5m 7s) (42000 84%) 0.8532
27m 2s (- 4m 57s) (42250 84%) 0.9056
27m 9s (- 4m 47s) (42500 85%) 0.7939
27m 16s (- 4m 37s) (42750 85%) 0.8685
27m 22s (- 4m 27s) (43000 86%) 0.8675
27m 30s (- 4m 17s) (43250 86%) 0.8868
27m 37s (- 4m 7s) (43500 87%) 0.8165
27m 44s (- 3m 57s) (43750 87%) 0.7273
27m 51s (- 3m 47s) (44000 88%) 0.8150
27m 58s (- 3m 38s) (44250 88%) 0.8015
28m 5s (- 3m 28s) (44500 89%) 0.7703
28m 13s (- 3m 18s) (44750 89%) 0.8699
28m 20s (- 3m 8s) (45000 90%) 0.8267
28m 27s (- 2m 59s) (45250 90%) 0.7528
28m 34s (- 2m 49s) (45500 91%) 0.8305
28m 41s (- 2m 39s) (45750 91%) 0.7830
28m 49s (- 2m 30s) (46000 92%) 0.8001
28m 56s (- 2m 20s) (46250 92%) 0.7384
29m 3s (- 2m 11s) (46500 93%) 0.7825
29m 10s (- 2m 1s) (46750 93%) 0.7710
29m 17s (- 1m 52s) (47000 94%) 0.7454
29m 24s (- 1m 42s) (47250 94%) 0.7490
29m 31s (- 1m 33s) (47500 95%) 0.8604
29m 38s (- 1m 23s) (47750 95%) 0.7776
29m 45s (- 1m 14s) (48000 96%) 0.7263
29m 53s (- 1m 5s) (48250 96%) 0.8098
30m 0s (- 0m 55s) (48500 97%) 0.6916
30m 8s (- 0m 46s) (48750 97%) 0.7064
30m 16s (- 0m 37s) (49000 98%) 0.8158
30m 23s (- 0m 27s) (49250 98%) 0.7894
30m 31s (- 0m 18s) (49500 99%) 0.7465
30m 39s (- 0m 9s) (49750 99%) 0.7975
30m 47s (- 0m 0s) (50000 100%) 0.7190
<Figure size 432x288 with 0 Axes>

evaluate_and_show_attention("elle a cinq ans de moins que moi .", encoder, decoder)
evaluate_and_show_attention("elle est trop petit .", encoder, decoder)
evaluate_and_show_attention("je ne crains pas de mourir .", encoder, decoder)
evaluate_and_show_attention("c est un jeune directeur plein de talent .", encoder, decoder)
input = elle a cinq ans de moins que moi .
output = she is two years younger than me . <EOS>

input = elle est trop petit .
output = she is too drunk . <EOS>

input = je ne crains pas de mourir .
output = i m not afraid of making mistakes . <EOS>

input = c est un jeune directeur plein de talent .
output = he s a very talented writer . <EOS>

2.1 Diving into LSTM
2.1.1 Implement your own LSTM from scratch using pytorch

@ 指的是 matrix mipliplication
class NaiveLSTM(nn.Module):
"""Naive LSTM like nn.LSTM"""
def __init__(self, input_size: int, hidden_size: int):
super(NaiveLSTM, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# input gate
self.w_ii = Parameter(Tensor(hidden_size, input_size))
self.w_hi = Parameter(Tensor(hidden_size, hidden_size))
self.b_ii = Parameter(Tensor(hidden_size, 1))
self.b_hi = Parameter(Tensor(hidden_size, 1))
# forget gate
self.w_if = Parameter(Tensor(hidden_size, input_size))
self.w_hf = Parameter(Tensor(hidden_size, hidden_size))
self.b_if = Parameter(Tensor(hidden_size, 1))
self.b_hf = Parameter(Tensor(hidden_size, 1))
# output gate
self.w_io = Parameter(Tensor(hidden_size, input_size))
self.w_ho = Parameter(Tensor(hidden_size, hidden_size))
self.b_io = Parameter(Tensor(hidden_size, 1))
self.b_ho = Parameter(Tensor(hidden_size, 1))
# cell
self.w_ig = Parameter(Tensor(hidden_size, input_size))
self.w_hg = Parameter(Tensor(hidden_size, hidden_size))
self.b_ig = Parameter(Tensor(hidden_size, 1))
self.b_hg = Parameter(Tensor(hidden_size, 1))
self.reset_weigths()
def reset_weigths(self):
"""reset weights
"""
stdv = 1.0 / math.sqrt(self.hidden_size)
for weight in self.parameters():
init.uniform_(weight, -stdv, stdv)
def forward(self, inputs: Tensor, state: Tuple[Tensor]) \
-> Tuple[Tensor, Tuple[Tensor, Tensor]]:
"""Forward
Args:
inputs: [1, 1, input_size]
state: ([1, 1, hidden_size], [1, 1, hidden_size])
"""
# seq_size, batch_size, _ = inputs.size()
if state is None:
h_t = torch.zeros(1, self.hidden_size).t()
c_t = torch.zeros(1, self.hidden_size).t()
else:
(h, c) = state
h_t = h.squeeze(0).t()
c_t = c.squeeze(0).t()
hidden_seq = []
seq_size = 1
for t in range(seq_size):
x = inputs[:, t, :].t()
# input gate
i = torch.sigmoid(self.w_ii @ x + self.b_ii + self.w_hi @ h_t +
self.b_hi)
# forget gate
f = torch.sigmoid(self.w_if @ x + self.b_if + self.w_hf @ h_t +
self.b_hf)
# cell
g = torch.tanh(self.w_ig @ x + self.b_ig + self.w_hg @ h_t
+ self.b_hg)
# output gate
o = torch.sigmoid(self.w_io @ x + self.b_io + self.w_ho @ h_t +
self.b_ho)
c_next = f * c_t + i * g
h_next = o * torch.tanh(c_next)
c_next_t = c_next.t().unsqueeze(0)
h_next_t = h_next.t().unsqueeze(0)
hidden_seq.append(h_next_t)
hidden_seq = torch.cat(hidden_seq, dim=0)
return hidden_seq, (h_next_t, c_next_t)
def reset_weigths(model):
"""reset weights
"""
for weight in model.parameters():
init.constant_(weight, 0.5)
inputs = torch.ones(1, 1, 10)
h0 = torch.ones(1, 1, 20)
c0 = torch.ones(1, 1, 20)
print(h0.shape, h0)
print(c0.shape, c0)
print(inputs.shape, inputs)
torch.Size([1, 1, 20]) tensor([[[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1.]]])
torch.Size([1, 1, 20]) tensor([[[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1.]]])
torch.Size([1, 1, 10]) tensor([[[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]]])
# test naive_lstm with input_size=10, hidden_size=20
naive_lstm = NaiveLSTM(10, 20)
reset_weigths(naive_lstm)
output1, (hn1, cn1) = naive_lstm(inputs, (h0, c0))
print(hn1.shape, cn1.shape, output1.shape)
print(hn1)
print(cn1)
print(output1)
torch.Size([1, 1, 20]) torch.Size([1, 1, 20]) torch.Size([1, 1, 20])
tensor([[[0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640,
0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640,
0.9640, 0.9640, 0.9640, 0.9640]]], grad_fn=<UnsqueezeBackward0>)
tensor([[[2.0000, 2.0000, 2.0000, 2.0000, 2.0000, 2.0000, 2.0000, 2.0000,
2.0000, 2.0000, 2.0000, 2.0000, 2.0000, 2.0000, 2.0000, 2.0000,
2.0000, 2.0000, 2.0000, 2.0000]]], grad_fn=<UnsqueezeBackward0>)
tensor([[[0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640,
0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640,
0.9640, 0.9640, 0.9640, 0.9640]]], grad_fn=<CatBackward>)
2.1.2 Compare with Official LSTM
# Use official lstm with input_size=10, hidden_size=20
lstm = nn.LSTM(10, 20)
reset_weigths(lstm)
output2, (hn2, cn2) = lstm(inputs, (h0, c0))
print(hn2.shape, cn2.shape, output2.shape)
print(hn2)
print(cn2)
print(output2)
torch.Size([1, 1, 20]) torch.Size([1, 1, 20]) torch.Size([1, 1, 20])
tensor([[[0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640,
0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640,
0.9640, 0.9640, 0.9640, 0.9640]]], grad_fn=<StackBackward>)
tensor([[[2.0000, 2.0000, 2.0000, 2.0000, 2.0000, 2.0000, 2.0000, 2.0000,
2.0000, 2.0000, 2.0000, 2.0000, 2.0000, 2.0000, 2.0000, 2.0000,
2.0000, 2.0000, 2.0000, 2.0000]]], grad_fn=<StackBackward>)
tensor([[[0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640,
0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640, 0.9640,
0.9640, 0.9640, 0.9640, 0.9640]]], grad_fn=<StackBackward>)
2.2 Observing the Grad Vanishing of LSTM and RNN
# Implementation of RNN for our experiment
from NaiveRNN import NaiveRNN
hidden_size = 50
input_size = 100
sequence_len = 100
high = 1000000
# Generate random input with sequence_len=100
test_idx = torch.randint(high=high, size=(1, sequence_len)).to(device)
print(test_idx)
tensor([[467641, 438165, 935784, 348843, 456126, 678722, 544521, 629650, 913052,
515704, 359498, 813691, 85030, 812238, 81280, 534390, 213301, 739639,
946166, 142993, 176025, 324614, 504309, 253316, 20391, 536403, 934167,
390225, 640486, 736492, 462829, 287346, 267072, 136907, 162403, 581682,
251738, 852900, 377706, 95229, 817013, 533409, 486543, 639531, 823225,
393774, 451828, 300227, 620261, 894586, 392700, 298598, 399744, 551383,
934141, 695864, 855742, 290926, 663304, 578266, 672847, 429797, 580725,
394330, 248653, 28963, 842417, 337341, 445876, 271879, 831151, 824026,
226680, 804180, 468878, 716080, 324929, 540810, 686717, 493021, 133503,
913081, 488010, 758172, 446451, 518270, 381352, 378181, 296251, 519946,
205581, 921540, 626297, 817562, 742148, 732258, 934476, 589189, 638731,
298330]], device='cuda:0')
setup_seed(45)
embeddings = nn.Embedding(high, input_size).to(device)
test_embeddings = embeddings(test_idx).to(device)
print(test_embeddings)
h_0 = torch.zeros(1, hidden_size, requires_grad=True).to(device)
h_t = h_0
print(h_0)
print(test_embeddings)
tensor([[[ 0.5697, 0.7304, -0.4647, ..., 0.7549, 0.3112, -0.4582],
[ 1.5171, 0.7328, 0.0803, ..., 1.2385, 1.2259, -0.5259],
[-0.2804, -0.4395, 1.5441, ..., -0.8644, 0.1858, -0.9446],
...,
[ 0.5019, -0.8431, -0.9560, ..., 0.2607, 1.2035, 0.6892],
[-0.5062, 0.8530, 0.3743, ..., -0.4148, -0.3384, 0.9264],
[-2.1523, 0.6292, -0.9732, ..., -0.2591, -1.6320, -0.1915]]],
device='cuda:0', grad_fn=<EmbeddingBackward>)
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0.]], device='cuda:0', grad_fn=<CopyBackwards>)
tensor([[[ 0.5697, 0.7304, -0.4647, ..., 0.7549, 0.3112, -0.4582],
[ 1.5171, 0.7328, 0.0803, ..., 1.2385, 1.2259, -0.5259],
[-0.2804, -0.4395, 1.5441, ..., -0.8644, 0.1858, -0.9446],
...,
[ 0.5019, -0.8431, -0.9560, ..., 0.2607, 1.2035, 0.6892],
[-0.5062, 0.8530, 0.3743, ..., -0.4148, -0.3384, 0.9264],
[-2.1523, 0.6292, -0.9732, ..., -0.2591, -1.6320, -0.1915]]],
device='cuda:0', grad_fn=<EmbeddingBackward>)
2.2.1 Grad of RNN
def rnn_step(x, h, w_ih, b_ih, w_hh, b_hh):
"""run rnn a step
"""
h = torch.tanh(w_ih @ x.t() + b_ih + w_hh @ h.t() + b_hh)
h_t = h.t()
return h_t
print(test_embeddings)
rnn = NaiveRNN(input_size, hidden_size).to(device)
iters = test_embeddings.size(1)
rnn_grads = []
for t in range(iters):
h_t = rnn_step(test_embeddings[: , t, :], h_t,
rnn.w_ih, rnn.b_ih, rnn.w_hh, rnn.b_hh)
loss = h_t.abs().sum()
h_0.retain_grad()
loss.backward(retain_graph=True)
rnn_grads.append(torch.norm(h_0.grad).item())
h_0.grad.zero_()
rnn.zero_grad()
tensor([[[ 0.5697, 0.7304, -0.4647, ..., 0.7549, 0.3112, -0.4582],
[ 1.5171, 0.7328, 0.0803, ..., 1.2385, 1.2259, -0.5259],
[-0.2804, -0.4395, 1.5441, ..., -0.8644, 0.1858, -0.9446],
...,
[ 0.5019, -0.8431, -0.9560, ..., 0.2607, 1.2035, 0.6892],
[-0.5062, 0.8530, 0.3743, ..., -0.4148, -0.3384, 0.9264],
[-2.1523, 0.6292, -0.9732, ..., -0.2591, -1.6320, -0.1915]]],
device='cuda:0', grad_fn=<EmbeddingBackward>)
plt.plot(rnn_grads)
[<matplotlib.lines.Line2D at 0x7efff80f44a8>]

2.2.1 Grad of LSTM
def show_gates(i_s, o_s, f_s):
"""Show input gate, output gate, forget gate for LSTM
"""
plt.plot(i_s, "r", label="input gate")
plt.plot(o_s, "b", label="output gate")
plt.plot(f_s, "g", label="forget gate")
plt.title('Input gate, output gate and forget gate of LSTM')
plt.xlabel('t', color='#1C2833')
plt.ylabel('Mean Value', color='#1C2833')
plt.legend(loc='best')
plt.grid()
plt.show()
def lstm_step(x, h, c, w_ii, b_ii, w_hi, b_hi,
w_if, b_if, w_hf, b_hf,
w_ig, b_ig, w_hg, b_hg,
w_io, b_io, w_ho, b_ho, use_forget_gate=True):
"""run lstm a step
"""
x_t = x.t()
h_t = h.t()
c_t = c.t()
i = torch.sigmoid(w_ii @ x_t + b_ii + w_hi @ h_t + b_hi)
o = torch.sigmoid(w_io @ x_t + b_io + w_ho @ h_t + b_ho)
g = torch.tanh(w_ig @ x_t + b_ig + w_hg @ h_t + b_hg)
f = torch.sigmoid(w_if @ x_t + b_if + w_hf @ h_t + b_hf)
if use_forget_gate:
c_next = f * c_t + i * g
else:
c_next = c_t + i * g
h_next = o * torch.tanh(c_next)
c_next_t = c_next.t()
h_next_t = h_next.t()
i_avg = torch.mean(i).detach()
o_avg = torch.mean(o).detach()
f_avg = torch.mean(f).detach()
return h_next_t, c_next_t, f_avg, i_avg, o_avg
setup_seed(45)
embeddings = nn.Embedding(high, input_size).to(device)
test_embeddings = embeddings(test_idx).to(device)
h_0 = torch.zeros(1, hidden_size, requires_grad=True).to(device)
c_0 = torch.zeros(1, hidden_size, requires_grad=True).to(device)
h_t = h_0
c_t = c_0
print(test_embeddings)
print(h_0)
print(c_0)
tensor([[[ 0.5697, 0.7304, -0.4647, ..., 0.7549, 0.3112, -0.4582],
[ 1.5171, 0.7328, 0.0803, ..., 1.2385, 1.2259, -0.5259],
[-0.2804, -0.4395, 1.5441, ..., -0.8644, 0.1858, -0.9446],
...,
[ 0.5019, -0.8431, -0.9560, ..., 0.2607, 1.2035, 0.6892],
[-0.5062, 0.8530, 0.3743, ..., -0.4148, -0.3384, 0.9264],
[-2.1523, 0.6292, -0.9732, ..., -0.2591, -1.6320, -0.1915]]],
device='cuda:0', grad_fn=<EmbeddingBackward>)
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0.]], device='cuda:0', grad_fn=<CopyBackwards>)
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0.]], device='cuda:0', grad_fn=<CopyBackwards>)
2.2.2.1 Grad of LSTM (Not Using forget gate)
lstm = NaiveLSTM(input_size, hidden_size).to(device)
iters = test_embeddings.size(1)
lstm_grads = []
i_s = []
o_s = []
f_s = []
for t in range(iters):
h_t, c_t, f, i, o = lstm_step(test_embeddings[: , t, :], h_t, c_t,
lstm.w_ii, lstm.b_ii, lstm.w_hi, lstm.b_hi,
lstm.w_if, lstm.b_if, lstm.w_hf, lstm.b_hf,
lstm.w_ig, lstm.b_ig, lstm.w_hg, lstm.b_hg,
lstm.w_io, lstm.b_io, lstm.w_ho, lstm.b_ho,
use_forget_gate=False)
loss = h_t.abs().sum()
h_0.retain_grad()
loss.backward(retain_graph=True)
lstm_grads.append(torch.norm(h_0.grad).item())
i_s.append(i)
o_s.append(o)
f_s.append(f)
h_0.grad.zero_()
lstm.zero_grad()
plt.plot(lstm_grads)
[<matplotlib.lines.Line2D at 0x7efffb6d53c8>]

show_gates(i_s, o_s, f_s)

2.2.2.2 Grad of LSTM (Using forget gate)
setup_seed(45)
embeddings = nn.Embedding(high, input_size).to(device)
test_embeddings = embeddings(test_idx).to(device)
h_0 = torch.zeros(1, hidden_size, requires_grad=True).to(device)
c_0 = torch.zeros(1, hidden_size, requires_grad=True).to(device)
h_t = h_0
c_t = c_0
print(test_embeddings)
print(h_0)
print(c_0)
tensor([[[ 0.5697, 0.7304, -0.4647, ..., 0.7549, 0.3112, -0.4582],
[ 1.5171, 0.7328, 0.0803, ..., 1.2385, 1.2259, -0.5259],
[-0.2804, -0.4395, 1.5441, ..., -0.8644, 0.1858, -0.9446],
...,
[ 0.5019, -0.8431, -0.9560, ..., 0.2607, 1.2035, 0.6892],
[-0.5062, 0.8530, 0.3743, ..., -0.4148, -0.3384, 0.9264],
[-2.1523, 0.6292, -0.9732, ..., -0.2591, -1.6320, -0.1915]]],
device='cuda:0', grad_fn=<EmbeddingBackward>)
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0.]], device='cuda:0', grad_fn=<CopyBackwards>)
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0.]], device='cuda:0', grad_fn=<CopyBackwards>)
lstm = NaiveLSTM(input_size, hidden_size).to(device)
## BIG CHANGE!!
lstm.b_hf.data = torch.ones_like(lstm.b_hf) * 1/2
lstm.b_if.data = torch.ones_like(lstm.b_if) * 1/2
iters = test_embeddings.size(1)
lstm_grads = []
i_s = []
o_s = []
f_s = []
for t in range(iters):
h_t, c_t, f, i, o = lstm_step(test_embeddings[: , t, :], h_t, c_t,
lstm.w_ii, lstm.b_ii, lstm.w_hi, lstm.b_hi,
lstm.w_if, lstm.b_if, lstm.w_hf, lstm.b_hf,
lstm.w_ig, lstm.b_ig, lstm.w_hg, lstm.b_hg,
lstm.w_io, lstm.b_io, lstm.w_ho, lstm.b_ho,
use_forget_gate=True)
loss = h_t.abs().sum()
h_0.retain_grad()
loss.backward(retain_graph=True)
lstm_grads.append(torch.norm(h_0.grad).item())
i_s.append(i)
o_s.append(o)
f_s.append(f)
h_0.grad.zero_()
lstm.zero_grad()
plt.plot(lstm_grads)
[<matplotlib.lines.Line2D at 0x7efff9599b70>]

show_gates(i_s, o_s, f_s)

Reference
- Seq2seq
- building-an-lstm-from-scratch-in-pytorch-lstms-in-depth-part-1
- seq2seq_translation_tutorial
- Understanding-LSTMs
- pytorch-seq2seq
做了无加分的作业
- 使用GRU加速Seq2seq的训练速度。请简单修改以下几个函数,不要改变函数形参。并且重复使用它重复作业1.1。 (5+4个cell)
Hints: 相对LSTM,GRU做了优化。它将LSTM的两个输入hidden和cell用同一个参数hidden表示。目的是降低计算开销,劣势是会牺牲一定的精度。 - 简答,课件实现的seq2seq和 Sequence to Sequence Learning with Neural Networks 的有什么差别?论文中模型训练开销是多久?有什么简单的办法可以提升训练速度吗?(开放性问题, 1个cell)
EncoderLSTM -> EncoderGRU, 将nn.LSTM换成nn.GRU
DecoderLSTM -> DecoderGRU, 将nn.LSTM换成nn.GRU
train_by_sentence -> train_by_sentence_v2
train -> train_v2
evaluate -> train_v2