Introduction
One of the most debated topics in deep learning is how to interpret and understand a trained model – particularly in the context of high risk industries like healthcare. The term “black box” has often been associated with deep learning algorithms. How can we trust the results of a model if we can’t explain how it works? It’s a legitimate question. Take the example of a deep learning model trained for detecting cancerous tumours. The model tells you that it is 99% sure that it has detected cancer – but it does not tell you why or how it made that decision.Did it find an important clue in the MRI scan? Or was it just a smudge on the scan that was incorrectly detected as a tumour? This is a matter of life and death for the patient and doctors cannot afford to be wrong.
Next, we will explore how to visualize a convolutional neural network (CNN), a deep learning architecture particularly used in most state-of-the-art image based applications. We will get to know the importance of visualizing a CNN model, and the methods to visualize them. We will also take a look at a use case that will help you understand the concept better.
Note: Here I assume that you know the basics of deep learning and have previously worked on image processing problems using CNN such training a classifier on specified dataset. This code is written in PyTorch with CPU version(version 0.4.1) but also work in version 1.0.0. For more details of source code, please check my GitHub repository(Welcome stars).
Table of Contents
- Importance of Visualizing a CNN model
- Methods of Visualization
- Preliminary Methods
- Plot Model Architecture
- Classes Prototype Generation
- Gradient based Methods
- Saliency Map
- Feature activation map
- Class Activation Map
- Gradient-weighted Class Activation Map
- Preliminary Methods
- Discussions
Importance of Visualizing a CNN model
As we have seen in the cancerous tumour example above, it is absolutely crucial that we know what our model is doing – and how it’s making decisions on its predictions. Typically, the reasons listed below are the most important points for a deep learning practitioner to remember:
- Understanding how the model works
- Assistance in Hyperparameter tuning
- Finding out the failures of the model and getting an intuition of why they fail
- Explaining the reasons behind the given decisions.
Methods of Visualizing a CNN model
Broadly the methods of Visualizing a CNN model can be categorized into three parts based on their internal workings:
- Preliminary methods – Simple methods which show us the overall structure of a trained model
- Activation based methods – In these methods, we decipher the activations of the individual neurons or a group of neurons to get an intuition of what they are doing
- Gradient based methods – These methods tend to manipulate the gradients that are formed from a forward and backward pass while training a model
Note: All experiments use MNIST dataset for simplification in default, where CPU environment is enough to cope with training and visulizing neural networks. The visulization on neural networks usually needs to train a classifier(not end-to-end) in advance, which is well understandable. Hence, for better readability in this presentation, we will not show the snippets of training classifier on MNIST and only point out where corresponding scripts lie such that you also can get access to full code.
All is done. Let’s start the course now.
1. Preliminary Methods
1.1 Plotting model architecture
The simplest thing you can do is to print/plot the model. Here, you can also print the shapes of individual layers of neural network and the parameters in each layer. In PyTorch, you can install a external library called torchsummaryX, which can print the details conveniently such as layers name and toal params. Let’s take the example of plotting the model architecture of AlexNet:
# pip install torchsummaryX
from torchsummaryX import summary
from torchvision.models import alexnet, resnet34, resnet50, densenet121, vgg16, vgg19, resnet18
import torch
device = torch.device("cuda:1")
summary(alexnet(pretrained=False), torch.zeros((1, 3, 224, 224)))
=======================================================================================
Kernel Shape Output Shape Params (K) \
Layer
0_features.Conv2d_0 [3, 64, 11, 11] [1, 64, 55, 55] 23.296
1_features.ReLU_1 - [1, 64, 55, 55] -
2_features.MaxPool2d_2 - [1, 64, 27, 27] -
3_features.Conv2d_3 [64, 192, 5, 5] [1, 192, 27, 27] 307.392
4_features.ReLU_4 - [1, 192, 27, 27] -
5_features.MaxPool2d_5 - [1, 192, 13, 13] -
6_features.Conv2d_6 [192, 384, 3, 3] [1, 384, 13, 13] 663.936
7_features.ReLU_7 - [1, 384, 13, 13] -
8_features.Conv2d_8 [384, 256, 3, 3] [1, 256, 13, 13] 884.992
9_features.ReLU_9 - [1, 256, 13, 13] -
10_features.Conv2d_10 [256, 256, 3, 3] [1, 256, 13, 13] 590.08
11_features.ReLU_11 - [1, 256, 13, 13] -
12_features.MaxPool2d_12 - [1, 256, 6, 6] -
13_classifier.Dropout_0 - [1, 9216] -
14_classifier.Linear_1 [9216, 4096] [1, 4096] 37752.8
15_classifier.ReLU_2 - [1, 4096] -
16_classifier.Dropout_3 - [1, 4096] -
17_classifier.Linear_4 [4096, 4096] [1, 4096] 16781.3
18_classifier.ReLU_5 - [1, 4096] -
19_classifier.Linear_6 [4096, 1000] [1, 1000] 4097
Mult-Adds (M)
Layer
0_features.Conv2d_0 70.2768
1_features.ReLU_1 -
2_features.MaxPool2d_2 -
3_features.Conv2d_3 223.949
4_features.ReLU_4 -
5_features.MaxPool2d_5 -
6_features.Conv2d_6 112.14
7_features.ReLU_7 -
8_features.Conv2d_8 149.52
9_features.ReLU_9 -
10_features.Conv2d_10 99.6803
11_features.ReLU_11 -
12_features.MaxPool2d_12 -
13_classifier.Dropout_0 -
14_classifier.Linear_1 37.7487
15_classifier.ReLU_2 -
16_classifier.Dropout_3 -
17_classifier.Linear_4 16.7772
18_classifier.ReLU_5 -
19_classifier.Linear_6 4.096
---------------------------------------------------------------------------------------
Params (K): 61100.84
Mult-Adds (M): 714.18848
=======================================================================================
| Kernel Shape | Output Shape | Params (K) | Mult-Adds (M) | |
|---|---|---|---|---|
| Layer | ||||
| 0_features.Conv2d_0 | [3, 64, 11, 11] | [1, 64, 55, 55] | 23.296 | 70.276800 |
| 1_features.ReLU_1 | - | [1, 64, 55, 55] | NaN | NaN |
| 2_features.MaxPool2d_2 | - | [1, 64, 27, 27] | NaN | NaN |
| 3_features.Conv2d_3 | [64, 192, 5, 5] | [1, 192, 27, 27] | 307.392 | 223.948800 |
| 4_features.ReLU_4 | - | [1, 192, 27, 27] | NaN | NaN |
| 5_features.MaxPool2d_5 | - | [1, 192, 13, 13] | NaN | NaN |
| 6_features.Conv2d_6 | [192, 384, 3, 3] | [1, 384, 13, 13] | 663.936 | 112.140288 |
| 7_features.ReLU_7 | - | [1, 384, 13, 13] | NaN | NaN |
| 8_features.Conv2d_8 | [384, 256, 3, 3] | [1, 256, 13, 13] | 884.992 | 149.520384 |
| 9_features.ReLU_9 | - | [1, 256, 13, 13] | NaN | NaN |
| 10_features.Conv2d_10 | [256, 256, 3, 3] | [1, 256, 13, 13] | 590.080 | 99.680256 |
| 11_features.ReLU_11 | - | [1, 256, 13, 13] | NaN | NaN |
| 12_features.MaxPool2d_12 | - | [1, 256, 6, 6] | NaN | NaN |
| 13_classifier.Dropout_0 | - | [1, 9216] | NaN | NaN |
| 14_classifier.Linear_1 | [9216, 4096] | [1, 4096] | 37752.832 | 37.748736 |
| 15_classifier.ReLU_2 | - | [1, 4096] | NaN | NaN |
| 16_classifier.Dropout_3 | - | [1, 4096] | NaN | NaN |
| 17_classifier.Linear_4 | [4096, 4096] | [1, 4096] | 16781.312 | 16.777216 |
| 18_classifier.ReLU_5 | - | [1, 4096] | NaN | NaN |
| 19_classifier.Linear_6 | [4096, 1000] | [1, 1000] | 4097.000 | 4.096000 |
From the printed abstract, we can know lots of basic information about AlexNet such as total parameters(61,100.84K), all layers in details including name, input/output channels, parameters and kernel size.
2. Classes Prototype Generation
Taking the example of classification tasks, given a random image, a trained model can predict its category correctly. We may take it for granted that this model seems to have learnt distinctively semantic features especially when the image is classfied correctly with high score. However, This conclusion may fail under the interference of complex external factors such as highly variant background environment where the classifier may make decision by surrounding objects rather than main object itself. In other word, we need another way to check whether the classifier really learn distinctively semantic features for all classes. A popular way to achieve this is to generate its corresponding prototypes for all classes, which contain the most fundamental information about features. Hence, generated class prototype will be more likely to filter the irrelevant information and focus on the main object itself.
2.1 Create Neural Network
Firstly, we build a plain neural network only contraining 3 fully connected layers. For more details, please check the scirpt class_prototype/model.py.
from torch import nn
class MNIST_DNN(nn.Module):
def __init__(self):
super(MNIST_DNN, self).__init__()
self.dense1 = nn.Linear(784, 512)
self.dense2 = nn.Linear(512, 100)
self.dense3 = nn.Linear(100, 10)
def forward(self, x):
x = self.dense1(x)
x = self.dense2(x)
x = self.dense3(x)
return x
2.2 Training Clssifier
Before achieving this intersting idea, we need to train a classifier firstly. Here we train a simply fully connected network with best accuracy=93.1% on testing sets.
2.3 Generate Classes Prototype
Regarding to the best accuray=93.1% on testing sets, actually this is a poor performance on MNIST because we only build a fully connected network and do nothing with optimization even no activation function.
Next we will generate corresponding classes prototype for all categories from digit 0 to digit 9. To do this, we need a few tricks as following:
- Initializing input with random noise. Here, we initialize input from standard normal distribution.
- Freezing except updating the initial input the parameters of model in backpropagation stage.
To make the distribution of input closer to the distribution of real data, we also calculate the mean squared error between pixel-wise mean for each categories and input as regularization term, which is defined by $z$. Therefore, the loss function is as following:
where we use $f(.)$ denote the pretrained model, $x$ denote the input, $y$ denote corresponding label, $cross_entropy$ and $mse_loss$ denote cross entropy error and mean squared error, repectively. Note that we need to set the mode of this model to eval.
import torch
from torch.autograd import Variable
from torch import nn, optim
import matplotlib.pyplot as plt
import numpy as np
from class_prototype.model import MNIST_DNN
from utils.utils import set_parameters_static
from utils.utils import get_img_means
lmda = 0.1
class Prototype(nn.Module):
def __init__(self):
super(Prototype, self).__init__()
criterion = nn.CrossEntropyLoss()
regular = nn.MSELoss()
model = MNIST_DNN()
model.load_state_dict(torch.load('./class_prototype/MNIST_CNN.pkl'))
# don't update parameters of original model
model = set_parameters_static(model)
model = model.to(device)
# init images and labels:0-9
x_prototype = torch.zeros(10, 784).to(device)
y_prototype = torch.linspace(0, 9, 10)
y_prototype = y_prototype.type(torch.LongTensor).to(device)
x_prototype = Variable(x_prototype, requires_grad=True)
y_prototype = Variable(y_prototype)
imgs_means = get_img_means('./dataset/mnist').to(device)
imgs_means = Variable(imgs_means)
optimizer = optim.Adam([x_prototype], lr=0.01)
print('begin training...')
for i in range(10000):
optimizer.zero_grad()
logits_prototype = model(x_prototype)
cost_protype = criterion(logits_prototype, y_prototype) + lmda * regular(x_prototype, imgs_means)
cost_protype.backward()
optimizer.step()
if i % 500 == 0:
print('cost_protype={:.6f}'.format(cost_protype.item()))
begin training...
cost_protype=3.027935
cost_protype=0.004735
cost_protype=0.003305
cost_protype=0.002228
cost_protype=0.001450
cost_protype=0.000912
cost_protype=0.000562
cost_protype=0.000353
cost_protype=0.000238
cost_protype=0.000181
cost_protype=0.000156
cost_protype=0.000147
cost_protype=0.000143
cost_protype=0.000143
cost_protype=0.000143
cost_protype=0.000142
cost_protype=0.000143
cost_protype=0.000142
cost_protype=0.000142
cost_protype=0.000142
We use pretrained weights to initialize this classifier. Then freeze the model parameters and only train input tensor using Adam optimizer, where the loss decrease stably until 0.0001. After training for 10000 steps, we can show class prototype using plot package as following.
x_prototype = x_prototype.data.cpu().numpy()
assert x_prototype.shape == (10, 784)
plt.figure(figsize=(7, 7))
for i in range(5):
left = x_prototype[2*i,:].reshape(28, 28)
plt.subplot(5, 2, 2 * i +1)
plt.imshow(left, cmap='gray', interpolation='none')
plt.title('Digit:{}'.format(2 * i))
plt.colorbar()
right = x_prototype[2*i+1,:].reshape(28, 28)
plt.subplot(5, 2, 2 * i + 2)
plt.imshow(right, cmap='gray', interpolation='none')
plt.title('Digit:{}'.format(2 * i + 1))
plt.colorbar()
plt.tight_layout()
plt.show()

3 Gradient based Methods
In gradient-based algorithms, the gradient of the output with respect to the input is used for constructing the saliency maps. The algorithms in this class differ in the way the gradients are modified during backpropagation. Relevance score based algorithms try to attribute the relevance of each input pixel by backpropagating the probability score instead of the gradient. However, all of these methods involve a single forward and backward pass through the net to generate heatmaps as opposed to multiple forward passes for the perturbation based methods. Evidently, all of these methods are computationally cheaper as well as free of artifacts originating from perturbation techniques.
3.1 Saliency Map
In this section we describe how a classification ConvNet can be queried about the spatial support of a particular class in a given image. Given an image $I_0$, a class $c$, and a classification ConvNet with the class score function $S_c(I)$, we would like to rank the pixels of $I_0$ based on their influence on the score $S_c(I_0)$.
We start with a motivational example. Consider the linear score model for the class $c$:
where the image I is represented in the vectorised (one-dimensional) form, and wc and bc are respectively the weight vector and the bias of the model. In this case, it is easy to see that the magnitude of elements of w defines the importance of the corresponding pixels of I for the class $c$.
In the case of deep ConvNets, the class score $S_c(I)$ is a highly non-linear function of $I$, so the reasoning of the previous paragraph can not be immediately applied. However, given an image $I_0$, we can approximate $S_c(I)$ with a linear function in the neighbourhood of $I_0$ by computing the first-order Taylor expansion:
where $w$ is the derivative of $S_c$ with respect to the image $I$ at the point (image) $I_0$:
3.1.1 Train CNN Classifier
Similarly, we build and train a CNN classifier well. The whole process including CNN definition also is listed as following. Because the code of training classifier actually is greatly similar, you also can just skim to and focus on the processing of computing saliency maps for digit from 0 to 9. For fully source code of training classifier, please check the script sensitivity_analysis/training.py.
import torch
from torch.autograd import Variable
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch import nn, optim
class MNIST_CNN(nn.Module):
def __init__(self):
super(MNIST_CNN, self).__init__()
self.layer1 = nn.Sequential(nn.Conv2d(1, 32, 3, stride=1, padding=1), nn.ReLU(True),
nn.MaxPool2d(2, 2, padding=1), nn.Dropout(p=0.7))
self.layer2 = nn.Sequential(nn.Conv2d(32, 64, 3, stride=1, padding=1), nn.ReLU(True),
nn.MaxPool2d(2, 2, padding=1), nn.Dropout(p=0.7))
self.layer3 = nn.Sequential(nn.Conv2d(64, 128, 3, stride=1, padding=1), nn.ReLU(True),
nn.MaxPool2d(2, 2, padding=1), nn.Dropout(p=0.7))
self.layer4 = nn.Sequential(nn.Linear(128 * 5 * 5, 625), nn.ReLU(True),
nn.Dropout(0.5))
self.layer5 = nn.Sequential(nn.Linear(625, 10))
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = x.view(-1, 128 * 5 * 5)
x = self.layer4(x)
x = self.layer5(x)
return x
3.1.2 Compute saliency maps
After training the CNN classfier successfully with best accuracy =99.3% on testing sets, we will compute the derivative of CNN output scores with respect to the input images from digit 0 to digit 9.
import torch
from torch.autograd import Variable
from sensitivity_analysis.model import MNIST_CNN
from utils.utils import get_all_digit_imgs
import numpy as np
import matplotlib.pyplot as plt
# the model is trained and saved on gpu and load weight on cpu
is_training_on_gpu = True
model = MNIST_CNN()
if is_training_on_gpu:
weights = torch.load('sensitivity_analysis/cnn_weights.pkl', map_location=lambda storage, loc: storage)
else:
weights = torch.load('sensitivity_analysis/cnn_weights.pkl')
model.load_state_dict(weights)
model = model.to(device)
imgs = get_all_digit_imgs('./dataset/mnist').to(device)
print(imgs.shape)
imgs = Variable(imgs, requires_grad=True)
logits = model(imgs)
logits.backward(torch.ones(logits.size()).to(device))
gradients = imgs.grad.data.cpu().numpy()
torch.Size([10, 1, 28, 28])
Now, we can show the results using plt package.
assert gradients.shape == (10, 1, 28, 28)
gradients = np.squeeze(np.square(gradients), 1).reshape(10, 784)
sample_imgs = imgs.data.cpu().numpy()
plt.figure(figsize=(7, 7))
for i in range(5):
plt.subplot(5, 2, 2 * i +1)
plt.imshow(np.reshape(sample_imgs[2 * i,:], (28, 28)), cmap='gray')
plt.imshow(np.reshape(gradients[2 * i,:], (28, 28)), cmap='hot', alpha=0.5)
plt.title('Digit:{}'.format(2 * i))
plt.subplot(5, 2, 2 * i + 2)
plt.imshow(np.reshape(sample_imgs[2 *i + 1, :], (28, 28)), cmap='gray')
plt.imshow(np.reshape(gradients[2*i + 1, :], (28, 28)), cmap='hot', alpha=0.5)
plt.title('Digit:{}'.format(2 * i + 1))
plt.tight_layout()
plt.show()

4 Feature activation map
4.1 Class Activation Map(CAM)
CAM revisits the global average pooling layer(GAP), and sheds light on how it explicitly enables the convolutional neural network to have remarkable localization ability despite being trained on image-level labels.
Given a network architecture similar to ResNet18, where the network largely consists of convolutional layers, and just before the final output layer (softmax in the case of categorization), GAP is performed on the convolutional feature maps and use those as features for a fully-connected layer that produces the desired output (categorical or otherwise).
Given this simple connectivity structure, we can identify the importance of the image regions by projecting back the weights of the output layer on to the convolutional feature maps, a technique we call class activation mapping.
GAP outputs the spatial average of the feature map of each unit at the last convolutional layer. A weighted sum of these values is used to generate the final output. Similarly, we compute a weighted sum of the feature maps of the last convolutional layer to obtain our class activation maps. We describe this more formally below for the case of softmax.
For a given image, let $f_k(x, y)$ represent the activation of unit $k$ in the last convolutional layer at spatial location $(x, y)$. Then, for unit $k$, the result of performing global average pooling, $F_k$ is $\sum _{(x,y)}f_k(x, y)$. Thus, for a given class $c$, the input to the softmax, $S_c$, is $\sum_k w_c^kF_k$ where $w_c^k$ is the weight corresponding to class $c$ for unit $k$. Essentially, $w_c^k$ indicates the importance of $F_k$ for class $c$. Finally the output of the softmax for class $c$, Pc is given by $\frac{exp(S_c)}{ \sum_c exp(S_c)}$. Here we ignore the bias term: we explicitly set the input bias of the softmax to 0 as it has little to no impact on the classification performance.
By plugging $F_k=\sum _{(x,y)}f_k(x, y)$ into the class score, $S_c$, we obtain:
We define $M_c$ as the class activation map for class $c$, where each spatial element is given by:
Thus, $S_c = \sum_{(x,y)} M_c(x, y)$, and hence $M_c(x, y)$ directly indicates the importance of the activation at spatial grid $(x, y)$ leading to the classification of an image to class $c$.
Because class activation mappings needs to be applied on the network with GAP following last convolutional layer such as ResNet18. Here, we use pretrained model on ImageNet to visulize ResNet18 as a demo.
# simple implementation of CAM in PyTorch for the networks such as ResNet, DenseNet, SqueezeNet, Inception
import io
import requests
import matplotlib.pyplot as plt
from PIL import Image
from torchvision import models, transforms
from torch.autograd import Variable
from torch.nn import functional as F
import numpy as np
import cv2
# input image
LABELS_URL = 'https://s3.amazonaws.com/outcome-blog/imagenet/labels.json'
IMG_URL = 'http://media.mlive.com/news_impact/photo/9933031-large.jpg'
# networks such as googlenet, resnet, densenet already use global average pooling at the end, so CAM could be used directly.
model_id = 2
if model_id == 1:
net = models.squeezenet1_1(pretrained=True).to(device)
finalconv_name = 'features' # this is the last conv layer of the network
elif model_id == 2:
net = models.resnet18(pretrained=True).to(device)
finalconv_name = 'layer4'
elif model_id == 3:
net = models.densenet161(pretrained=True).to(device)
finalconv_name = 'features'
net.eval()
features_blobs = []
def hook_feature(module, input, output):
features_blobs.append(output.data.cpu().numpy())
net._modules.get(finalconv_name).register_forward_hook(hook_feature)
# get the softmax weight
params = list(net.parameters())
weight_softmax = np.squeeze(params[-2].data.cpu().numpy())
def returnCAM(feature_conv, weight_softmax, class_idx):
# generate the class activation maps upsample to 256x256
size_upsample = (256, 256)
bz, nc, h, w = feature_conv.shape
output_cam = []
for _ in class_idx:
cam = weight_softmax[class_idx].dot(feature_conv.reshape((nc, h*w)))
cam = cam.reshape(h, w)
cam = cam - np.min(cam)
cam_img = cam / np.max(cam)
cam_img = np.uint8(255 * cam_img)
output_cam.append(cv2.resize(cam_img, size_upsample))
return output_cam
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
preprocess = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
normalize
])
response = requests.get(IMG_URL)
img_pil = Image.open(io.BytesIO(response.content))
img_pil.save('./cam_based/test.jpg')
img_tensor = preprocess(img_pil).to(device)
img_variable = Variable(img_tensor.unsqueeze(0))
logit = net(img_variable)
# download the imagenet category list
classes = {int(key):value for (key, value)
in requests.get(LABELS_URL).json().items()}
h_x = F.softmax(logit, dim=1).data.squeeze()
probs, idx = h_x.sort(0, True)
# output the prediction
for i in range(0, 5):
print('{:.3f} -> {}'.format(probs[i], classes[idx[i].item()]))
# generate class activation mapping for the top1 prediction
CAMs = returnCAM(features_blobs[0], weight_softmax, [idx[0].item()])
# render the CAM and output
print('output CAM.jpg for the top1 prediction: %s'%classes[idx[0].item()])
img = cv2.imread('./cam_based/test.jpg')
height, width, _ = img.shape
heatmap = cv2.applyColorMap(cv2.resize(CAMs[0],(width, height)), cv2.COLORMAP_JET)
result = heatmap * 0.3 + img * 0.5
cv2.imwrite('./cam_based/CAM.jpg', result)
plt.imshow(Image.open('./cam_based/CAM.jpg'))
plt.axis('off')
plt.show()
0.437 -> mountain bike, all-terrain bike, off-roader
0.131 -> alp
0.119 -> bicycle-built-for-two, tandem bicycle, tandem
0.108 -> unicycle, monocycle
0.049 -> lakeside, lakeshore
output CAM.jpg for the top1 prediction: mountain bike, all-terrain bike, off-roader

4.2 Gradient-weighted Class Activation Mapping (Grad-CAM)
Another effective way to circumnavigate the backpropagation problems were explored in the Grad-CAM that was a generalization of CAM algorithm and can generate visual explanations from any CNN-based network without requiring architectural changes.
Let the feature maps in the final convolutional layers be $F_1$, $F_2$ … ,$F_n$. Like before assume image $I_0$, a class $c$, and a classification ConvNet with the class score function $S_c(I)$.
-
Weights ($w_1$, $w_2$ ,…, $w_n$) for each pixel in the $F_1$, $F_2$ … , $F_n$ is calculated based on the gradients class $c$ w.r.t. each feature map such as $w_i = \frac{\partial S_c}{\partial F} _{F_i} \ \forall i=1 \dots n$. - The weights and the corresponding activations of the feature maps are multiplied to compute the weighted activations ($A_1$,$A_2$, … , $A_n$) of each pixel in the feature maps. $A_i = w_i * F_i \ \forall i = 1 \dots n$
- The weighted activations across feature maps are added pixel-wise to indicate importance of each pixel in the downsampled feature-importance map $H_{i,j}$ as $H_{i,j} = \sum_{k=1}^{n}A_k(i,j) \ \forall i = 1 \dots n$.
Steps 1-4 makes up the GradCAM method. Here’s how a heat map generated from Grad CAM method looks like. The best contribution from the paper was the generalization of the CAM paper in the presence of fully-connected layers.
import matplotlib.pyplot as plt
import torch
from torch.autograd import Variable
from torch.autograd import Function
from torchvision import models
from torchvision import utils
import cv2
import sys
import numpy as np
class FeatureExtractor():
"""
Class for extracting activations and
registering gradients from targetted intermediate layers
"""
def __init__(self, model, target_layers):
self.model = model
self.target_layers = target_layers
self.gradients = []
def save_gradient(self, grad):
self.gradients.append(grad)
def __call__(self, x):
outputs = []
self.gradients = []
for name, module in self.model._modules.items():
x = module(x)
if name in self.target_layers:
x.register_hook(self.save_gradient)
outputs += [x]
return outputs, x
class ModelOutputs():
"""
Class for making a forward pass, and getting:
1. The network output.
2. Activations from intermeddiate targetted layers.
3. Gradients from intermeddiate targetted layers.
"""
def __init__(self, model, target_layers):
self.model = model
self.feature_extractor = FeatureExtractor(self.model.features, target_layers)
def get_gradients(self):
return self.feature_extractor.gradients
def __call__(self, x):
target_activations, output = self.feature_extractor(x)
output = output.view(output.size(0), -1)
output = self.model.classifier(output)
return target_activations, output
def preprocess_image(img):
means = [0.485, 0.456, 0.406]
stds = [0.229, 0.224, 0.225]
preprocessed_img = img.copy()[:, :, ::-1]
for i in range(3):
preprocessed_img[:, :, i] = preprocessed_img[:, :, i] - means[i]
preprocessed_img[:, :, i] = preprocessed_img[:, :, i] / stds[i]
preprocessed_img = \
np.ascontiguousarray(np.transpose(preprocessed_img, (2, 0, 1)))
preprocessed_img = torch.from_numpy(preprocessed_img)
preprocessed_img.unsqueeze_(0)
input = Variable(preprocessed_img, requires_grad=True)
return input
def show_cam_on_image(img, mask):
heatmap = cv2.applyColorMap(np.uint8(255 * mask), cv2.COLORMAP_JET)
heatmap = np.float32(heatmap) / 255
cam = heatmap + np.float32(img)
cam = cam / np.max(cam)
cv2.imwrite("./cam_based/grad_cam.jpg", np.uint8(255 * cam))
plt.imshow(Image.open('./cam_based/grad_cam.jpg'))
plt.axis('off')
plt.show()
class GradCam:
def __init__(self, model, target_layer_names, use_cuda):
self.model = model
self.model.eval()
self.cuda = use_cuda
if self.cuda:
self.model = model.cuda()
self.extractor = ModelOutputs(self.model, target_layer_names)
def forward(self, input):
return self.model(input)
def __call__(self, input, index=None):
if self.cuda:
features, output = self.extractor(input.cuda())
else:
features, output = self.extractor(input)
if index == None:
index = np.argmax(output.cpu().data.numpy())
one_hot = np.zeros((1, output.size()[-1]), dtype=np.float32)
one_hot[0][index] = 1
one_hot = Variable(torch.from_numpy(one_hot), requires_grad=True)
if self.cuda:
one_hot = torch.sum(one_hot.cuda() * output)
else:
one_hot = torch.sum(one_hot * output)
self.model.features.zero_grad()
self.model.classifier.zero_grad()
one_hot.backward(retain_graph=True)
grads_val = self.extractor.get_gradients()[-1].cpu().data.numpy()
target = features[-1]
target = target.cpu().data.numpy()[0, :]
weights = np.mean(grads_val, axis=(2, 3))[0, :]
cam = np.zeros(target.shape[1:], dtype=np.float32)
for i, w in enumerate(weights):
cam += w * target[i, :, :]
cam = np.maximum(cam, 0)
cam = cv2.resize(cam, (224, 224))
cam = cam - np.min(cam)
cam = cam / np.max(cam)
return cam
if __name__ == '__main__':
image_path = './cam_based/test.jpg'
# Can work with any model, but it assumes that the model has a
# feature method, and a classifier method,
# as in the VGG models in torchvision.
grad_cam = GradCam(model=models.vgg19(pretrained=True), target_layer_names=["35"], use_cuda=False)
img = cv2.imread(image_path, 1)
img = np.float32(cv2.resize(img, (224, 224))) / 255
input = preprocess_image(img)
# If None, returns the map for the highest scoring category.
# Otherwise, targets the requested index.
target_index = None
mask = grad_cam(input, target_index)
show_cam_on_image(img, mask)

Discussions
In this presentation, we introduct several methods to interpret neural network. We have so far understood both basic algorithms as well as gradient-based methods. Computationally and practically, the gradient-based methods are computationally cheaper and measure the contribution of the pixels in the neighborhood of the original image. For more methods, you can check these techniques as following:
Assignments
Q1: For class prototype generation, there is an interesting idea try to initialize the input tensor as digits directly such as digit 8 and the generation target are similar digits such as 3 and greate different digits such as 1 while the input is filled with zers in this presentation. Please perform this experiments.
Hints: You can use digit 8 as input, where a typical digit 8 image is saved in dataset/test_imgs/8.png.
Q2: In the visulization of CAM, the class activation map for class $c$, $M_c$, is calculated by the weighted($w^c$) product of all feature maps(512 feature maps in ResNet18) in last convolutional layer. Could you use the 20 feature maps with max activation value to visulize CNNs?
Hints:
- You can use arithmetic mean to indicate the activation value for one feature map.
- A recommendable way is to modify the function
returnCAM. - You need to have a clear understanding for the operation
slice.
Q3: Grad-CAM is the generation of CAM and it can visulize CNNs on multiple layers except for last convolutional layer. Please finish the visulization on the intermediate layer and the layer near the input.
Hints: You needn’t to rewrite code again. What you need to do is to understand that source code of Grad-CAM.
★★★ A1
In this question, we use digit 8 and 5 to generate 1 and 3 respectively, as shown in the following figures.

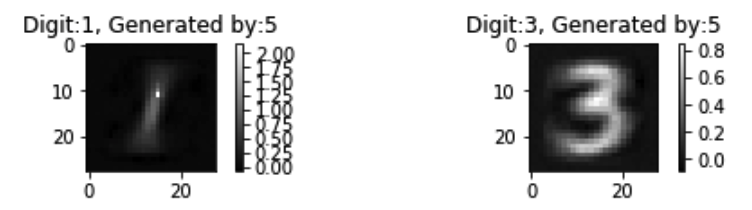
Note that there seems to be no differences, and the generated digits are good.
criterion = nn.CrossEntropyLoss()
regular = nn.MSELoss()
model = MNIST_DNN()
model.load_state_dict(torch.load('./class_prototype/MNIST_CNN.pkl'))
# don't update parameters of original model
model = set_parameters_static(model)
model = model.to(device)
eight = torch.from_numpy(cv2.cvtColor(cv2.imread('dataset/test_imgs/0.png'), cv2.COLOR_BGR2GRAY).reshape(1, 784)).type(torch.FloatTensor)
# init images and labels:0-9
x_prototype = torch.cat((eight, eight), 0).to(device)
y_prototype = torch.tensor([1, 3], dtype=torch.long)
y_prototype = y_prototype.type(torch.LongTensor).to(device)
x_prototype = Variable(x_prototype, requires_grad=True)
y_prototype = Variable(y_prototype)
imgs_means = get_img_means('./dataset/mnist')
imgs_means = torch.stack((imgs_means[1], imgs_means[3]), 0).to(device)
imgs_means = Variable(imgs_means)
optimizer = optim.Adam([x_prototype], lr=0.01)
print('begin training...')
for i in range(40000):
optimizer.zero_grad()
logits_prototype = model(x_prototype)
cost_protype = criterion(logits_prototype, y_prototype) + lmda * regular(x_prototype, imgs_means)
cost_protype.backward()
optimizer.step()
if i % 1000 == 0:
print('epoch={:5d}, cost_protype={:.6f}'.format(i, cost_protype.item()))
begin training...
epoch= 0, cost_protype=5159.575195
epoch= 1000, cost_protype=3365.842773
epoch= 2000, cost_protype=1832.016602
epoch= 3000, cost_protype=923.072876
epoch= 4000, cost_protype=877.491638
epoch= 5000, cost_protype=826.799622
epoch= 6000, cost_protype=770.023804
epoch= 7000, cost_protype=708.738525
epoch= 8000, cost_protype=645.313232
epoch= 9000, cost_protype=582.169861
epoch=10000, cost_protype=521.242310
epoch=11000, cost_protype=463.713898
epoch=12000, cost_protype=410.091736
epoch=13000, cost_protype=360.471405
epoch=14000, cost_protype=314.758820
epoch=15000, cost_protype=272.797913
epoch=16000, cost_protype=234.432938
epoch=17000, cost_protype=199.521515
epoch=18000, cost_protype=167.931992
epoch=19000, cost_protype=139.543686
epoch=20000, cost_protype=114.254707
epoch=21000, cost_protype=91.974586
epoch=22000, cost_protype=72.606750
epoch=23000, cost_protype=56.038528
epoch=24000, cost_protype=42.136402
epoch=25000, cost_protype=30.739347
epoch=26000, cost_protype=21.655951
epoch=27000, cost_protype=14.665687
epoch=28000, cost_protype=9.505931
epoch=29000, cost_protype=5.892412
epoch=30000, cost_protype=3.513893
epoch=31000, cost_protype=2.042986
epoch=32000, cost_protype=1.169959
epoch=33000, cost_protype=0.654425
epoch=34000, cost_protype=0.349468
epoch=35000, cost_protype=0.173513
epoch=36000, cost_protype=0.077236
epoch=37000, cost_protype=0.029056
epoch=38000, cost_protype=0.008297
epoch=39000, cost_protype=0.001537
x_prototype = x_prototype.data.cpu().numpy()
assert x_prototype.shape == (2, 784)
plt.figure(figsize=(7, 7))
right = x_prototype[0,:].reshape(28, 28)
plt.subplot(5, 2, 1)
plt.imshow(right, cmap='gray', interpolation='none')
plt.title('Digit:{}, Generated by:{}'.format(1, 8))
plt.colorbar()
right = x_prototype[1,:].reshape(28, 28)
plt.subplot(5, 2, 2)
plt.imshow(right, cmap='gray', interpolation='none')
plt.title('Digit:{}, Generated by:{}'.format(3, 8))
plt.colorbar()
plt.tight_layout()
plt.show()

criterion = nn.CrossEntropyLoss()
regular = nn.MSELoss()
model = MNIST_DNN()
model.load_state_dict(torch.load('./class_prototype/MNIST_CNN.pkl'))
# don't update parameters of original model
model = set_parameters_static(model)
model = model.to(device)
eight = torch.from_numpy(cv2.cvtColor(cv2.imread('dataset/test_imgs/0.png'), cv2.COLOR_BGR2GRAY).reshape(1, 784)).type(torch.FloatTensor)
# init images and labels:0-9
x_prototype = torch.cat((eight, eight), 0).to(device)
y_prototype = torch.tensor([1, 3], dtype=torch.long)
y_prototype = y_prototype.type(torch.LongTensor).to(device)
x_prototype = Variable(x_prototype, requires_grad=True)
y_prototype = Variable(y_prototype)
imgs_means = get_img_means('./dataset/mnist')
imgs_means = torch.stack((imgs_means[1], imgs_means[3]), 0).to(device)
imgs_means = Variable(imgs_means)
optimizer = optim.Adam([x_prototype], lr=0.01)
print('begin training...')
for i in range(40000):
optimizer.zero_grad()
logits_prototype = model(x_prototype)
cost_protype = criterion(logits_prototype, y_prototype) + lmda * regular(x_prototype, imgs_means)
cost_protype.backward()
optimizer.step()
if i % 1000 == 0:
print('epoch={:5d}, cost_protype={:.6f}'.format(i, cost_protype.item()))
begin training...
epoch= 0, cost_protype=5159.575195
epoch= 1000, cost_protype=3365.842773
epoch= 2000, cost_protype=1832.016602
epoch= 3000, cost_protype=923.072876
epoch= 4000, cost_protype=877.491638
epoch= 5000, cost_protype=826.799622
epoch= 6000, cost_protype=770.023804
epoch= 7000, cost_protype=708.738525
epoch= 8000, cost_protype=645.313232
epoch= 9000, cost_protype=582.169861
epoch=10000, cost_protype=521.242310
epoch=11000, cost_protype=463.713898
epoch=12000, cost_protype=410.091736
epoch=13000, cost_protype=360.471405
epoch=14000, cost_protype=314.758820
epoch=15000, cost_protype=272.797913
epoch=16000, cost_protype=234.432938
epoch=17000, cost_protype=199.521515
epoch=18000, cost_protype=167.931992
epoch=19000, cost_protype=139.543686
epoch=20000, cost_protype=114.254707
epoch=21000, cost_protype=91.974586
epoch=22000, cost_protype=72.606750
epoch=23000, cost_protype=56.038528
epoch=24000, cost_protype=42.136402
epoch=25000, cost_protype=30.739347
epoch=26000, cost_protype=21.655951
epoch=27000, cost_protype=14.665687
epoch=28000, cost_protype=9.505931
epoch=29000, cost_protype=5.892412
epoch=30000, cost_protype=3.513893
epoch=31000, cost_protype=2.042986
epoch=32000, cost_protype=1.169959
epoch=33000, cost_protype=0.654425
epoch=34000, cost_protype=0.349468
epoch=35000, cost_protype=0.173513
epoch=36000, cost_protype=0.077236
epoch=37000, cost_protype=0.029056
epoch=38000, cost_protype=0.008297
epoch=39000, cost_protype=0.001537
x_prototype = x_prototype.data.cpu().numpy()
assert x_prototype.shape == (2, 784)
plt.figure(figsize=(7, 7))
right = x_prototype[0,:].reshape(28, 28)
plt.subplot(5, 2, 1)
plt.imshow(right, cmap='gray', interpolation='none')
plt.title('Digit:{}, Generated by:{}'.format(1, 5))
plt.colorbar()
right = x_prototype[1,:].reshape(28, 28)
plt.subplot(5, 2, 2)
plt.imshow(right, cmap='gray', interpolation='none')
plt.title('Digit:{}, Generated by:{}'.format(3, 5))
plt.colorbar()
plt.tight_layout()
plt.show()

★★★ A2
Using 20 feature maps to visualize.
indexes = np.mean(feature_conv, axis=(1)).argsort()[::-1][0:20].

# input image
LABELS_URL = 'https://s3.amazonaws.com/outcome-blog/imagenet/labels.json'
IMG_URL = 'http://media.mlive.com/news_impact/photo/9933031-large.jpg'
# networks such as googlenet, resnet, densenet already use global average pooling at the end, so CAM could be used directly.
model_id = 2
if model_id == 1:
net = models.squeezenet1_1(pretrained=True).to(device)
finalconv_name = 'features' # this is the last conv layer of the network
elif model_id == 2:
net = models.resnet18(pretrained=True).to(device)
finalconv_name = 'layer4'
elif model_id == 3:
net = models.densenet161(pretrained=True).to(device)
finalconv_name = 'features'
net.eval()
features_blobs = []
def hook_feature(module, input, output):
features_blobs.append(output.data.cpu().numpy())
net._modules.get(finalconv_name).register_forward_hook(hook_feature)
# get the softmax weight
params = list(net.parameters())
weight_softmax = np.squeeze(params[-2].data.cpu().numpy())
def returnCAM(feature_conv, weight_softmax, class_idx):
# generate the class activation maps upsample to 256x256
size_upsample = (256, 256)
bz, nc, h, w = feature_conv.shape
output_cam = []
feature_conv = feature_conv.reshape((nc, h*w))
for _ in class_idx:
indexes = np.mean(feature_conv, axis=(1)).argsort()[::-1][0:20]
weights = np.array([[weight_softmax[class_idx][0][i] for i in indexes]])
features = np.array([feature_conv[i] for i in indexes])
cam = weights.dot(features)
cam = cam.reshape(h, w)
cam = cam - np.min(cam)
cam_img = cam / np.max(cam)
cam_img = np.uint8(255 * cam_img)
output_cam.append(cv2.resize(cam_img, size_upsample))
return output_cam
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
preprocess = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
normalize
])
response = requests.get(IMG_URL)
img_pil = Image.open(io.BytesIO(response.content))
img_pil.save('./cam_based/test.jpg')
img_tensor = preprocess(img_pil).to(device)
img_variable = Variable(img_tensor.unsqueeze(0))
logit = net(img_variable)
# download the imagenet category list
classes = {int(key):value for (key, value)
in requests.get(LABELS_URL).json().items()}
h_x = F.softmax(logit, dim=1).data.squeeze()
probs, idx = h_x.sort(0, True)
# output the prediction
for i in range(0, 5):
print('{:.3f} -> {}'.format(probs[i], classes[idx[i].item()]))
# generate class activation mapping for the top1 prediction
CAMs = returnCAM(features_blobs[0], weight_softmax, [idx[0].item()])
# render the CAM and output
print('output CAM.jpg for the top1 prediction: %s'%classes[idx[0].item()])
img = cv2.imread('./cam_based/test.jpg')
height, width, _ = img.shape
heatmap = cv2.applyColorMap(cv2.resize(CAMs[0],(width, height)), cv2.COLORMAP_JET)
result = heatmap * 0.3 + img * 0.5
cv2.imwrite('./cam_based/CAM.jpg', result)
plt.imshow(Image.open('./cam_based/CAM.jpg'))
plt.axis('off')
plt.show()
0.437 -> mountain bike, all-terrain bike, off-roader
0.131 -> alp
0.119 -> bicycle-built-for-two, tandem bicycle, tandem
0.108 -> unicycle, monocycle
0.049 -> lakeside, lakeshore
output CAM.jpg for the top1 prediction: mountain bike, all-terrain bike, off-roader

★★★ A3
The visualization of the layers is shown as follows.
if __name__ == '__main__':
image_path = './cam_based/test.jpg'
img = cv2.imread(image_path, 1)
img = np.float32(cv2.resize(img, (224, 224))) / 255
input = preprocess_image(img)
target_index = None
for i in range(37):
print("layer={}".format(i))
grad_cam = GradCam(model=models.vgg19(pretrained=True), target_layer_names=[str(i)], use_cuda=False)
mask = grad_cam(input, target_index)
show_cam_on_image(img, mask)
layer=0

layer=1

layer=2

layer=3

layer=4

layer=5

layer=6

layer=7

layer=8

layer=9

layer=10

layer=11

layer=12

layer=13

layer=14

layer=15

layer=16

layer=17

layer=18

layer=19

layer=20

layer=21
Reference
- https://www.analyticsvidhya.com/blog/2018/03/essentials-of-deep-learning-visualizing-convolutional-neural-networks/
- https://github.com/zhangrong1722/understanding_cnn
- http://blog.qure.ai/notes/deep-learning-visualization-gradient-based-methods#1509.06321
- Simonyan, K., Vedaldi, A., & Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034.
- Zeiler, M. D., & Fergus, R.. Visualizing and understanding convolutional networks. In ECCV.
- Selvaraju, R. R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., & Batra, D.. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. In CVPR.
- Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., & Torralba, A.. Learning deep features for discriminative localization. In CVPR.